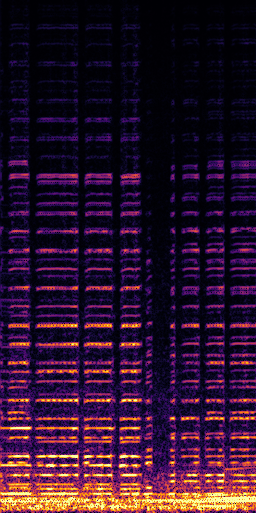
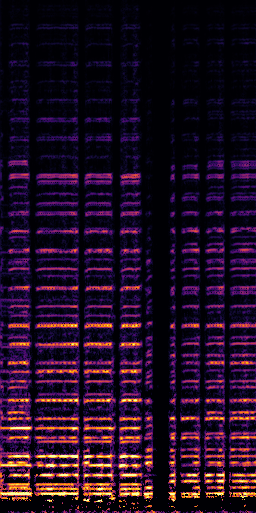
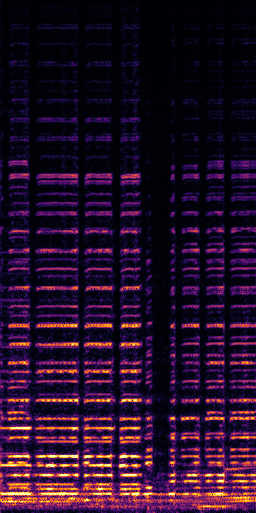
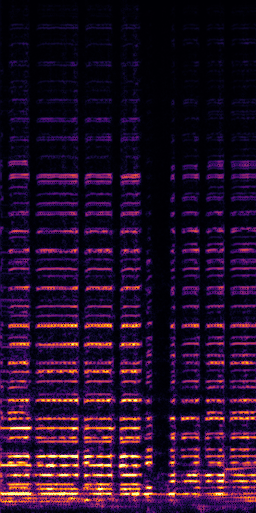
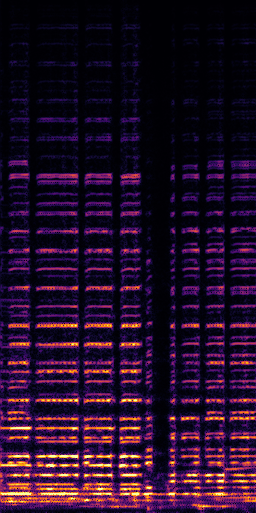
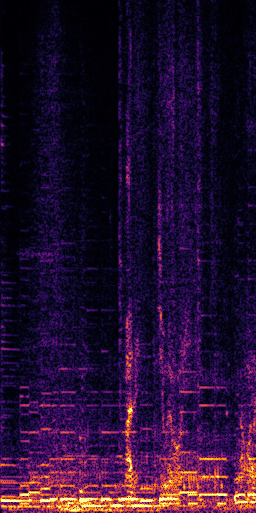
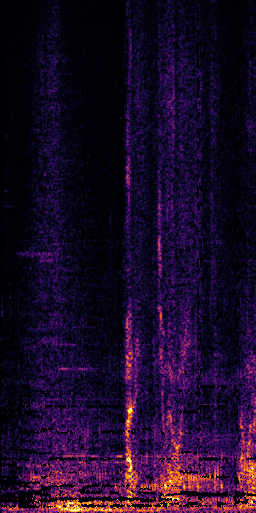
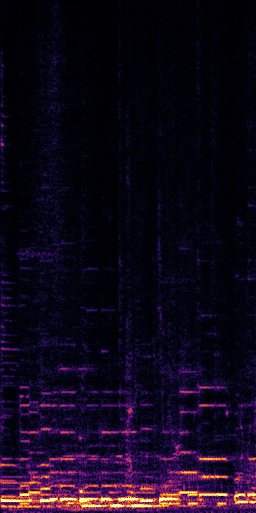
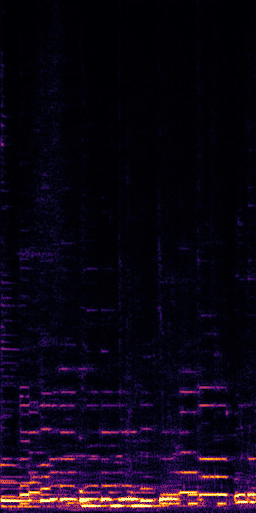
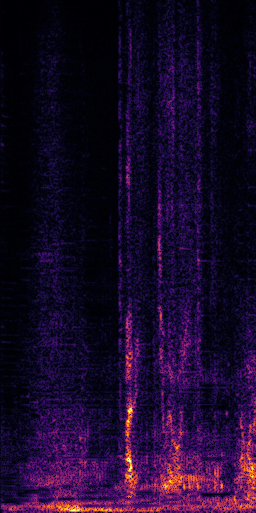
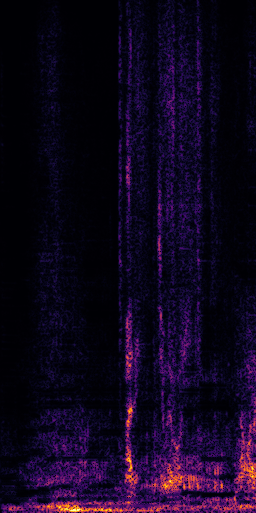
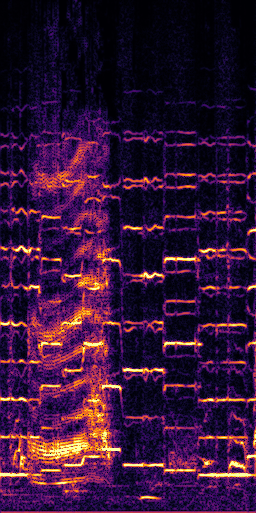
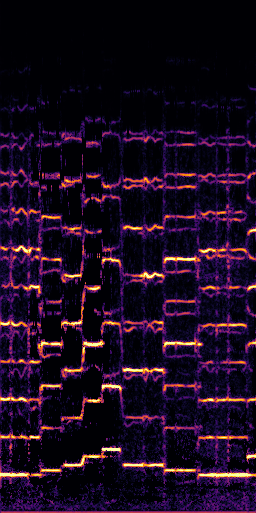
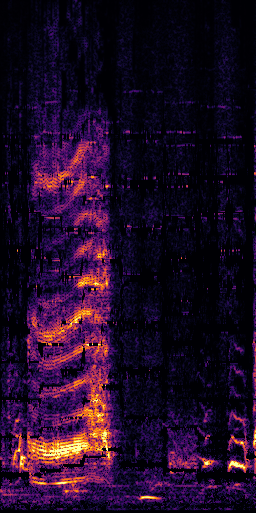
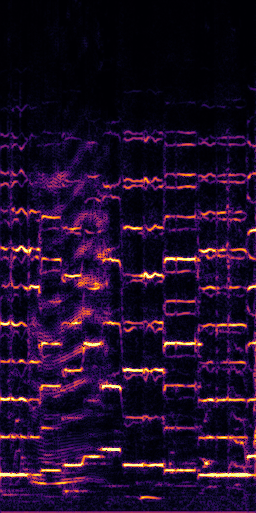
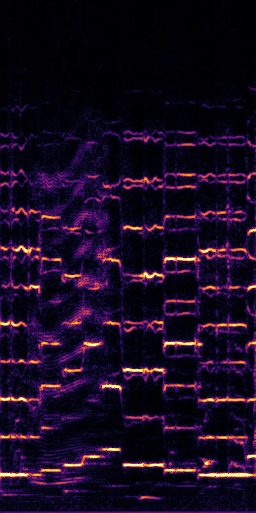
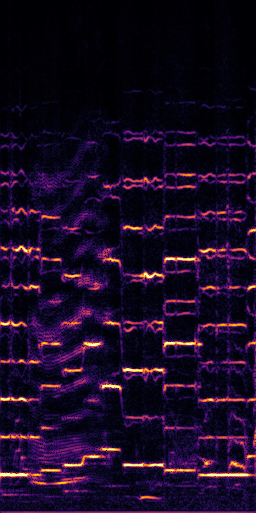
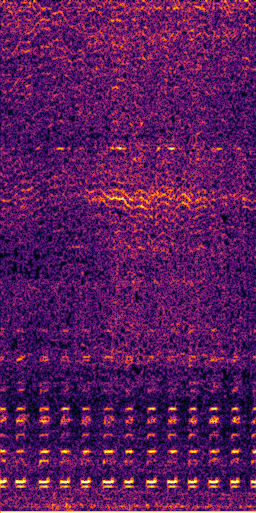
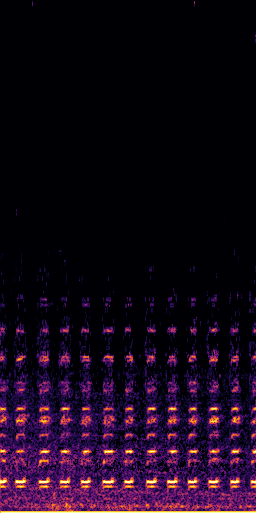
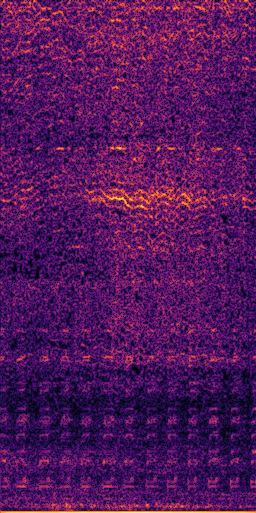
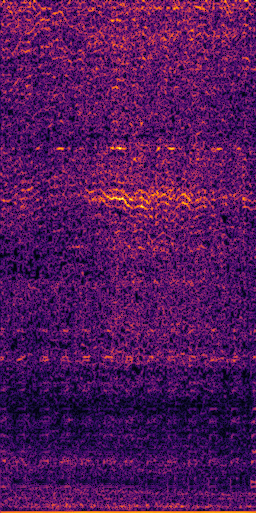
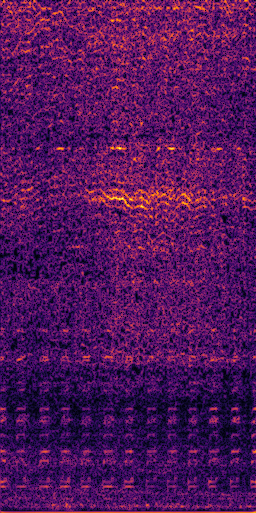
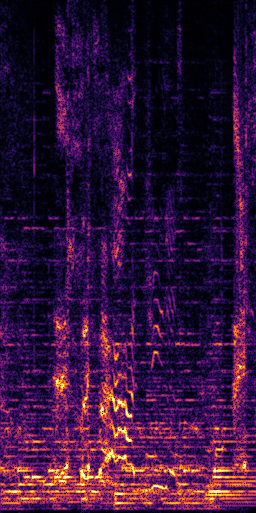
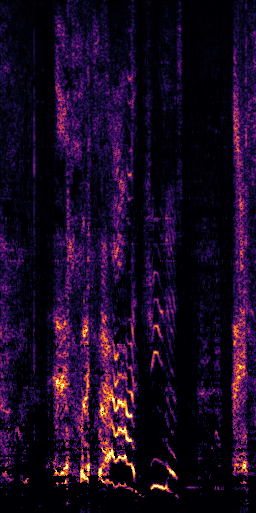
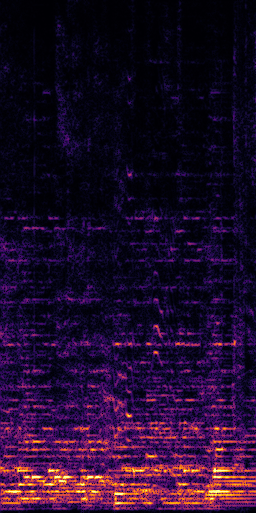
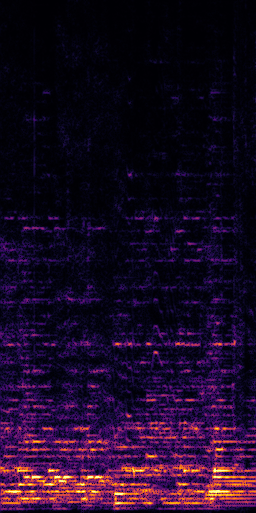
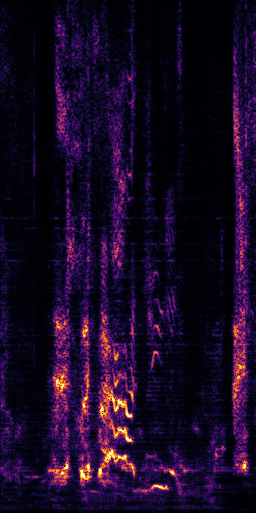
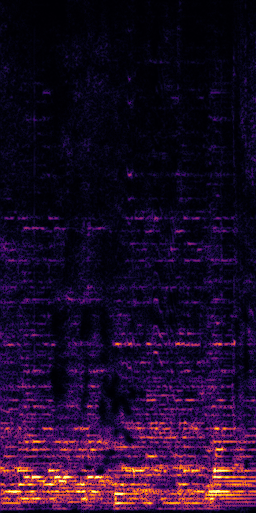
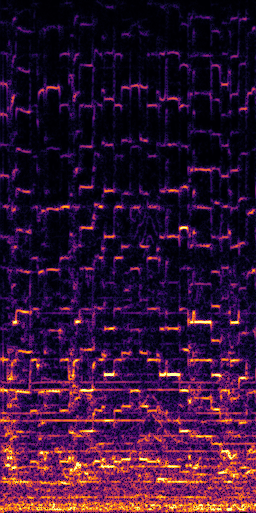
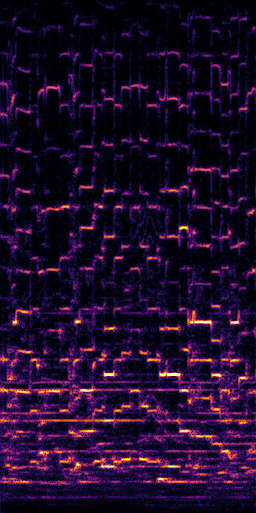
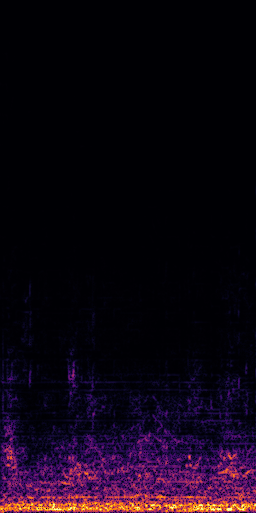
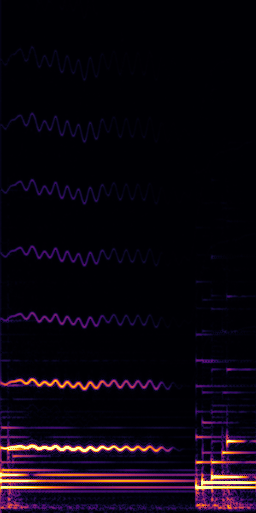
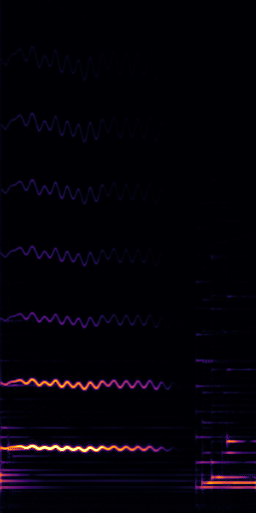
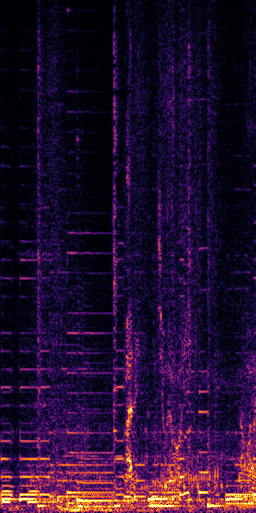
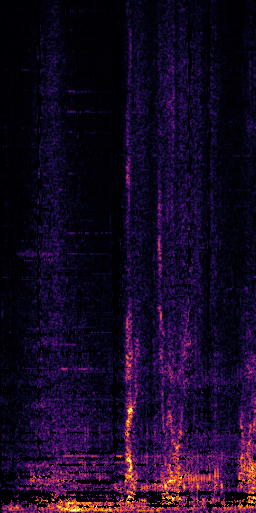
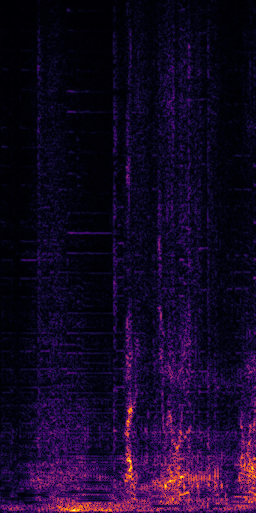
CLIPSep: Our proposed model without the noise invariant training.
CLIPSep-NIT: Our proposed model with the noise invariant training using γ = 0.25.
LabelSep: The proposed CLIPSep model with the query model replaced by a learnable embedding lookup table.
PIT: The permutation invariant training model proposed by Yu et al. (2017).1
Model
Unlabelled data
Post-processing free
Query type (training)
Query type (test)
CLIPSep
✓
✓
Image
Text
CLIPSep-NIT
✓
✓
Image
Text
LabelSep
✕
✓
Label
Label
PIT
✓
✕
-
-
Important notes
All the examples presented below use text queries rather than image queries.
We prefix the text query into the form of “a photo of [user input query]”.
All the spectrograms are shown in the log frequency scale.
Example results on “MUSIC + VGGSound”
Settings: We take an audio sample in the MUSIC dataset as the target source. We then mix the target source with an interference audio sample in the VGGSound dataset to create an artificial mixture.
Example 1 – “accordion” + “engine accelerating”
Target source: accordion
Interference: engine accelerating revving vroom
Query: “accordion”
Mixture
Ground truth
Ground truth (Interference)
Prediction (CLIPSep)
Prediction (CLIPSep-NIT)
Prediction (PIT)
Noise head 1 (CLIPSep-NIT) *
Noise head 2 (CLIPSep-NIT) *
* The noise heads are expected to contain query-irrelevant noises.
Example 2 – “acoustic guitar” + “cheetah chirrup”
Target source: acoustic guitar
Interference: cheetah chirrup
Query: “acoustic guitar”
Mixture
Ground truth
Ground truth (Interference)
Prediction (CLIPSep)
Prediction (CLIPSep-NIT)
Prediction (PIT) *
Noise head 1 (CLIPSep-NIT)
Noise head 2 (CLIPSep-NIT)
* The PIT model requires a post-selection step to get the correct source. Without the post-selection step, the PIT model return the right source in only a 50% chance.
Example 3 – “violin” + “people sobbing”
Target source: violin
Interference: people sobbing
Query: “violin”
Mixture
Ground truth
Ground truth (Interference)
Prediction (CLIPSep)
Prediction (CLIPSep-NIT)
Prediction (PIT)
Noise head 1 (CLIPSep-NIT)
Noise head 2 (CLIPSep-NIT)
Example results on “VGGSound-Clean + VGGSound”
Settings: We take an audio sample in the VGGSound-Clean dataset as the target source. We then mix the target source with an interference audio sample in the VGGSound dataset to create an artificial mixture. Note that the LabelSep model does not work on the MUSIC dataset due to the different label taxonomies of the MUSIC and VGGSound datasets.
Example 1 – “cat growling” + “railroad car”
Target source: cat growling
Interference: railroad car train wagon
Query: “cat growling”
Mixture
Ground truth
Ground truth (Interference)
Prediction (CLIPSep)
Prediction (CLIPSep-NIT)
Prediction (PIT)
Prediction (LabelSep)
Noise head 1 (CLIPSep-NIT) *
Noise head 2 (CLIPSep-NIT) *
* The noise heads are expected to contain query-irrelevant noises.
Example 2 – “electric grinder” + “car horn”
Target source: electric grinder grinding
Interference: vehicle horn car horn honking
Query: “electric grinder grinding”
Mixture
Ground truth
Ground truth (Interference)
Prediction (CLIPSep)
Prediction (CLIPSep-NIT)
Prediction (PIT) *
Prediction (LabelSep)
Noise head 1 (CLIPSep-NIT)
Noise head 2 (CLIPSep-NIT)
* The PIT model requires a post-selection step to get the correct source. Without the post-selection step, the PIT model return the right source in only a 50% chance.
Example 3 – “playing harpsichord” + “people coughing”
Target source: playing harpsichord
Interference: people coughing
Query: “playing harpsichord”
Mixture
Ground truth
Ground truth (Interference)
Prediction (CLIPSep)
Prediction (CLIPSep-NIT)
Prediction (PIT) *
Prediction (LabelSep)
Noise head 1 (CLIPSep-NIT)
Noise head 2 (CLIPSep-NIT)
* The PIT model requires a post-selection step to get the correct source. Without the post-selection step, the PIT model return the right source in only a 50% chance.
Example results on “VGGSound + None”
Settings: We take a “noisy” audio sample in the VGGSound dataset and treat it as the input mixture. We aim to examine if the model can separate the target sounds from query-irrelevant noises. Note that there is no “ground truth” in this setting.
Note: The model successfully separates most theremin sounds from the piano accompaniments.
Source video
Mixture
Prediction
Noise head 1
Noise head 2
Robustness to different queries
Settings: We take the same input mixture and query the model with different text queries to examine the model’s robustness to different queries. We use the CLIPSep-NIT model in this demo.
“acoustic guitar” + “cheetah chirrup”
Target source: acoustic guitar
Interference: cheetah chirrup
Note: We can see that the model is robust to different text queries and can extract the desired sounds.
Mixture
Ground truth
Ground truth (Interference)
Prediction (Query: “acoustic guitar”)
Prediction (Query: “guitar”)
Prediction (Query: “a man is playing acoustic guitar”)
Prediction (Query: “a man is playing acoustic guitar in a room”)
Prediction (Query: “car engine”)
Dong Yu, Morten Kolbæk, Zheng-Hua Tan, and Jesper Jensen. Permutation invariant training of deep models for speaker-independent multi-talker speech separation. In Proc. ICASSP, 2017. ↩