Method
| Conventional reinforcement learning | Constraints as Rewards (CaR) |
|---|---|
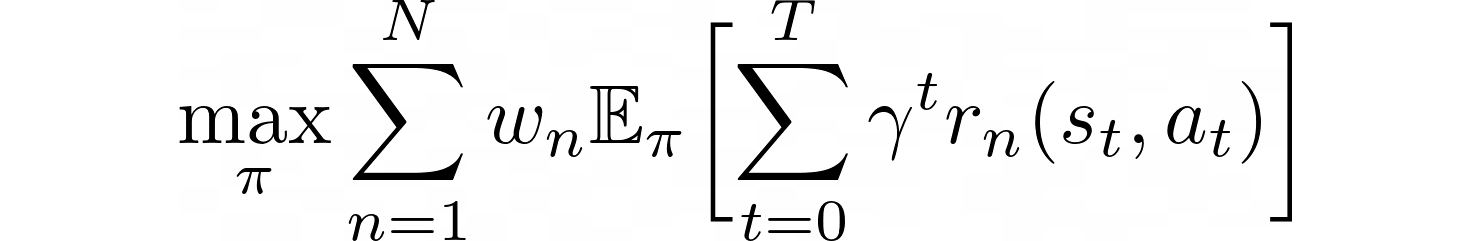 |
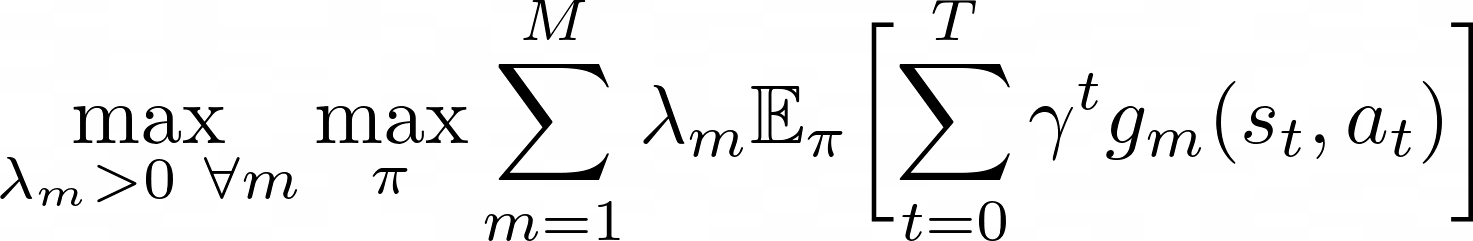 |
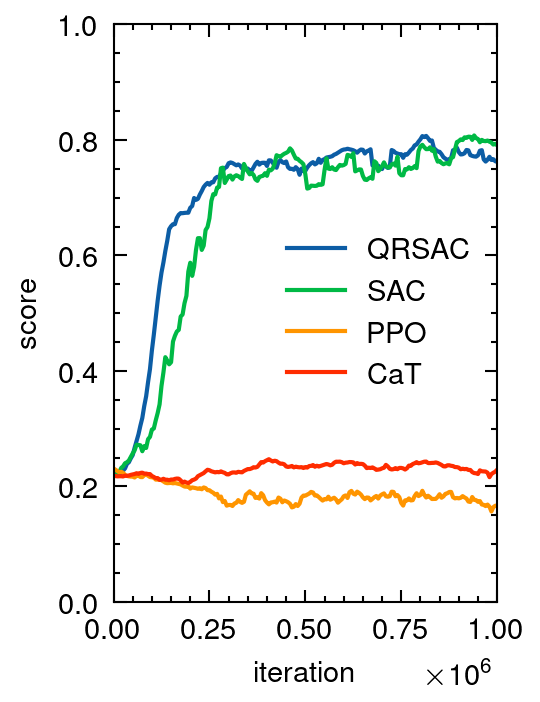
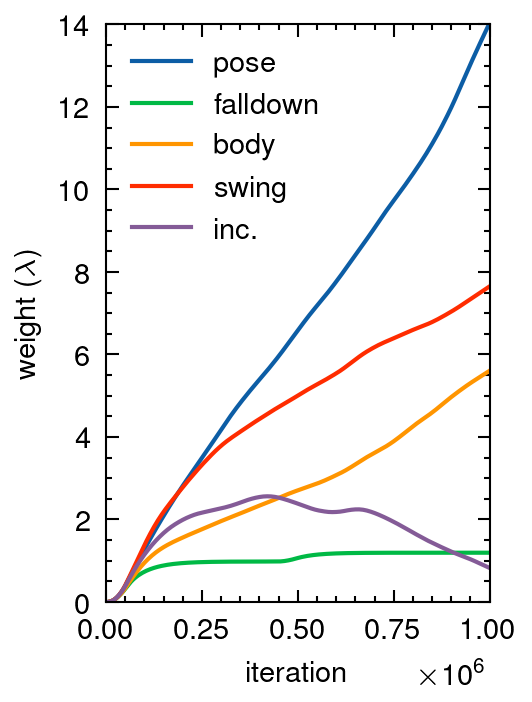
In many practical applications, reward functions are designed as a weighted sum of multiple functions. Therefore, conventional reinforcement learning solves the expression on the left. This typically involves extensive trial-and-error to tune the weights. To avoid this trial-and-error process, we propose solving the expression on the right. In the right expression, g_m(s,a) are constraint functions and lambdas are the Lagrange multipliers. The right expression suggests that, if we design the learning objective in terms of constraints, we can obtain the desired policy without tuning the weights among different objectives. We propose composing the learning objective with constraints to train the robot without manual tuning of weight parameters.