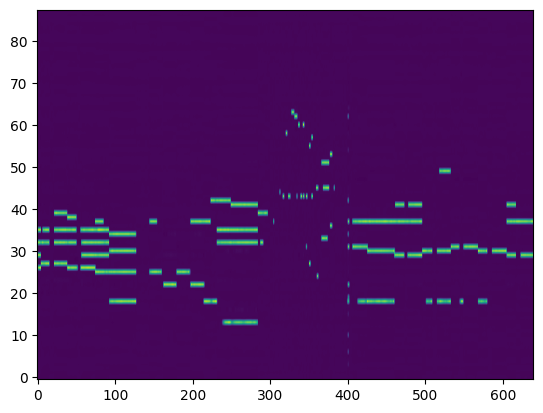
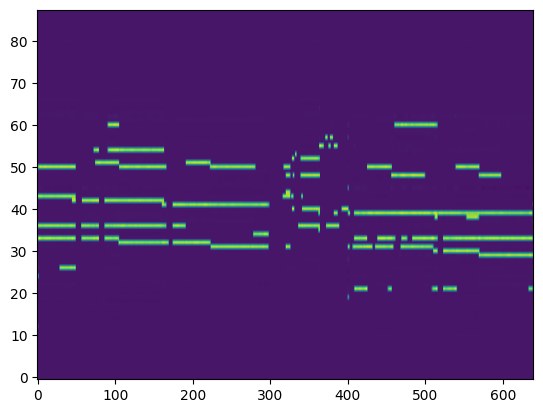
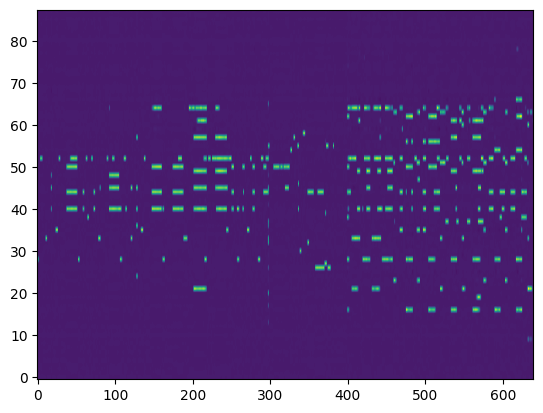
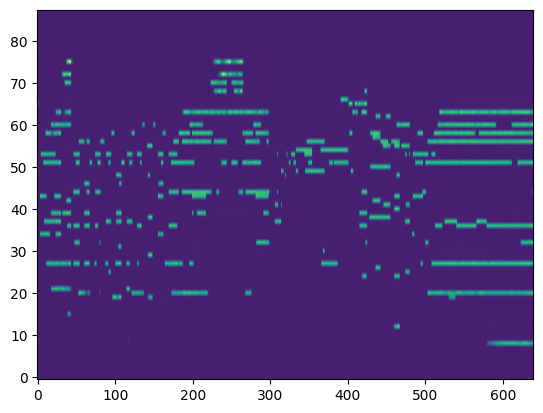
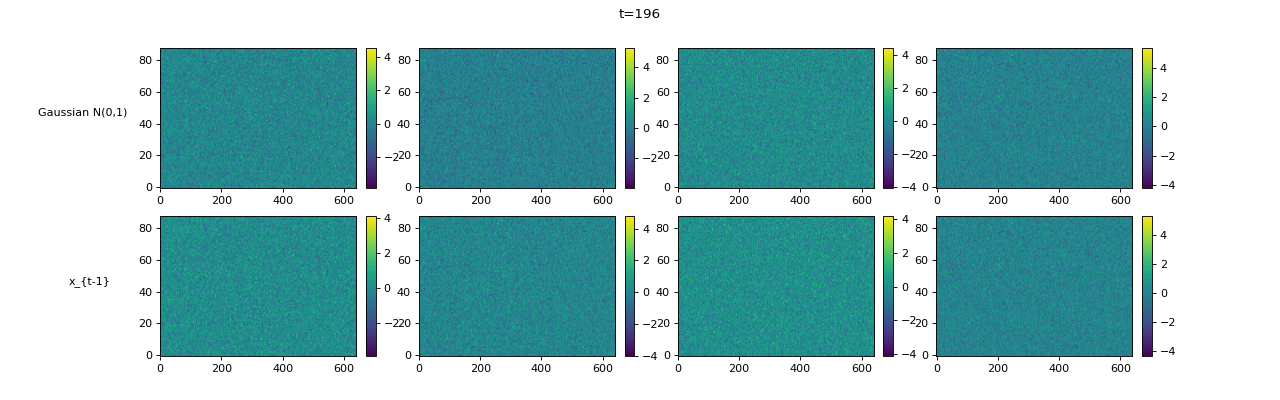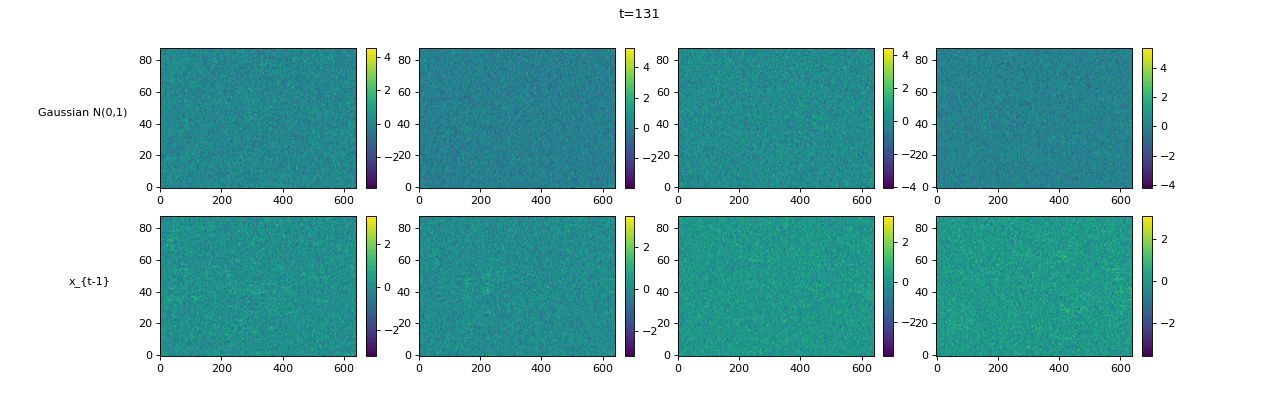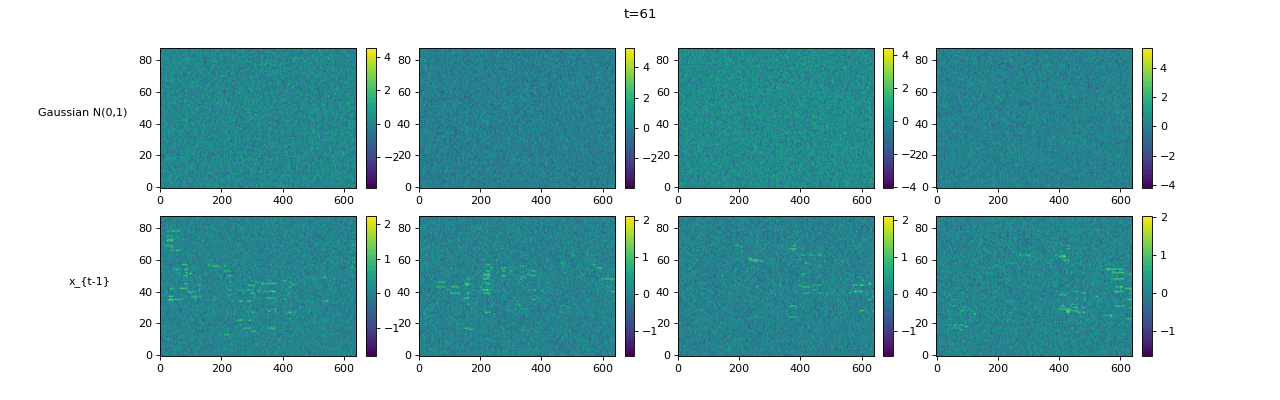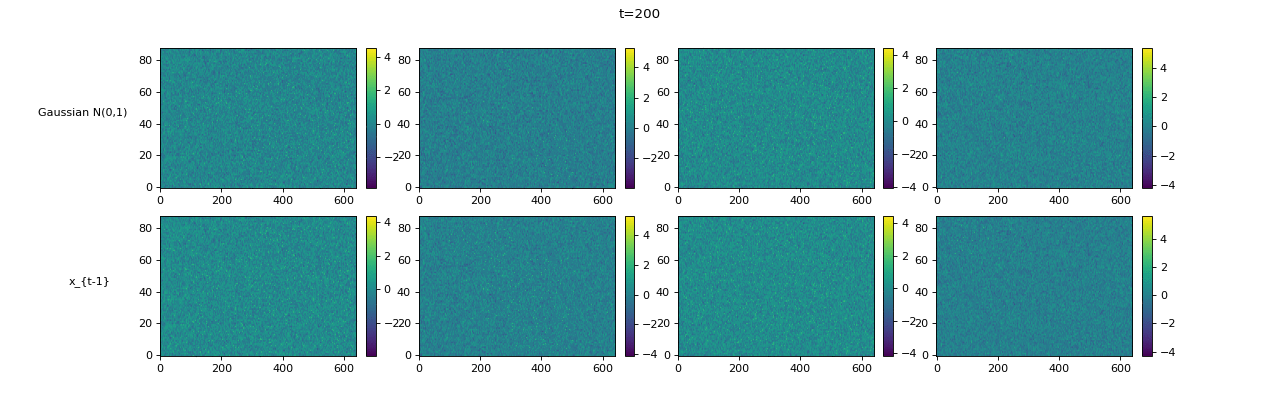
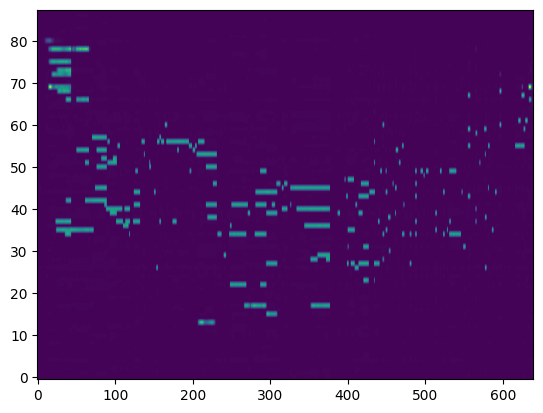
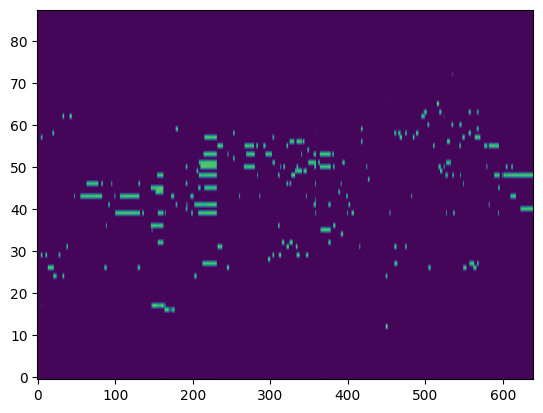
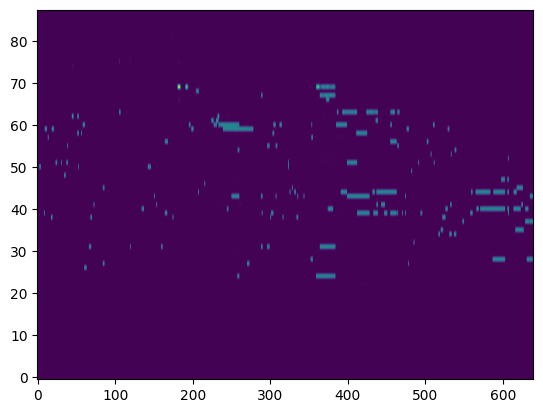
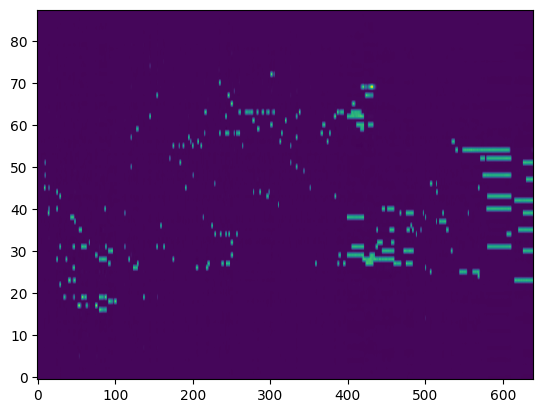
Transcription (Conditional Generation)¶
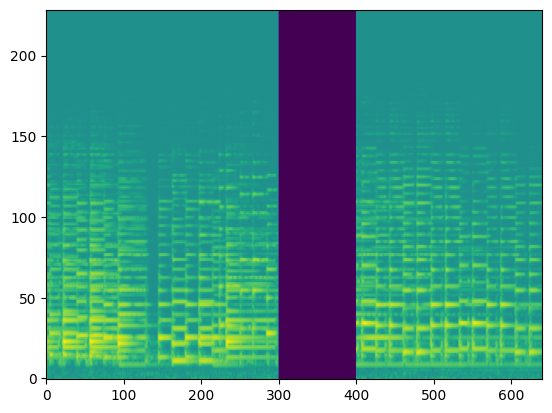
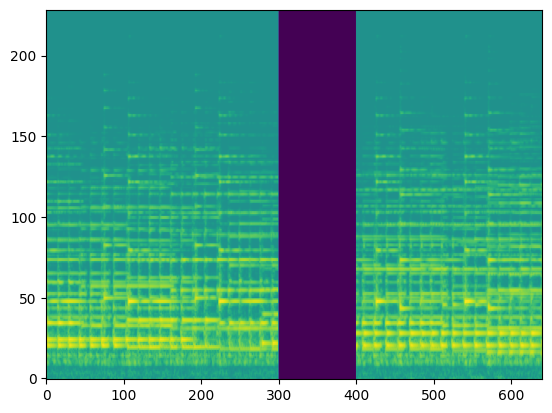
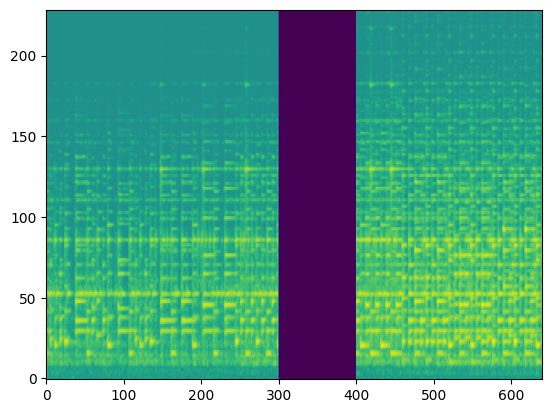
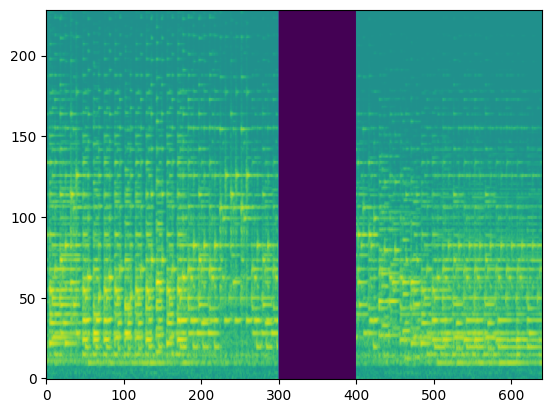
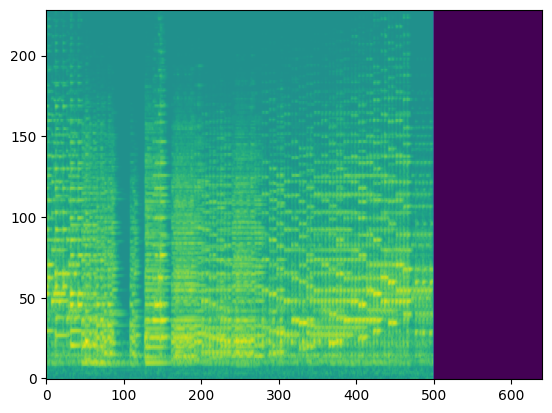
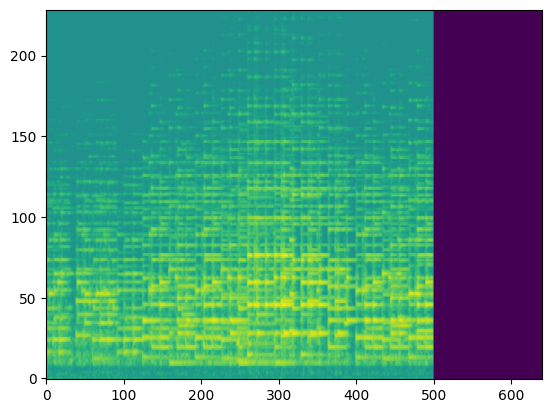
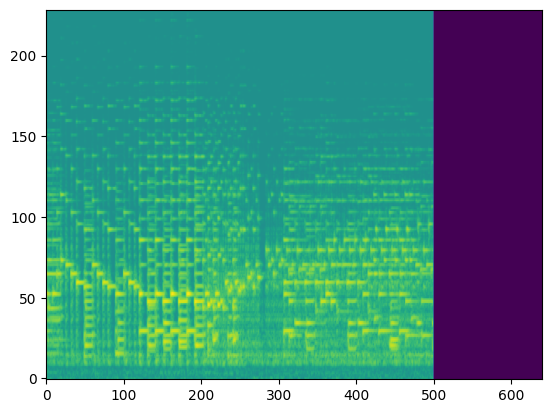
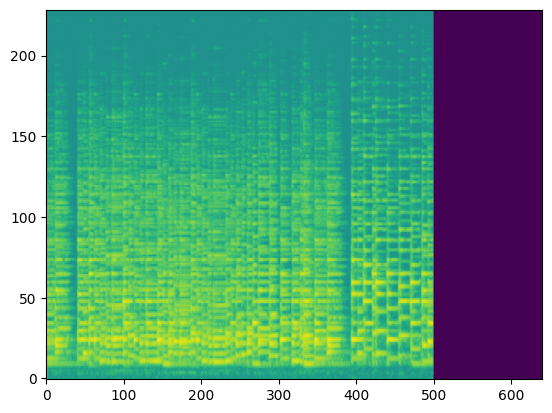
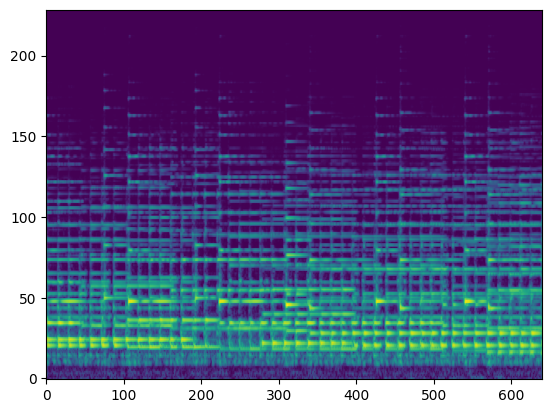
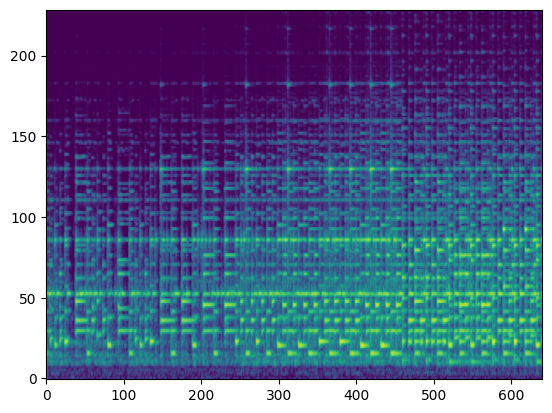
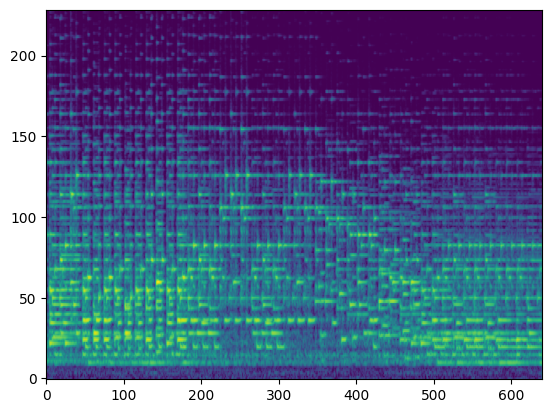
In this section, we use the spectrograms $x_\text{spec}$ as the condition of our model. By doing so, our model transcribes the spectrogram, but it can be also considered as conditional generation.
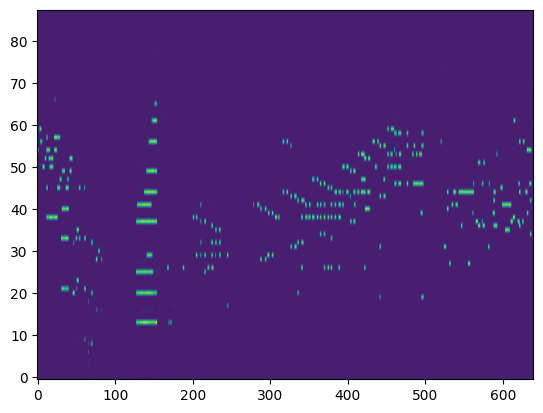
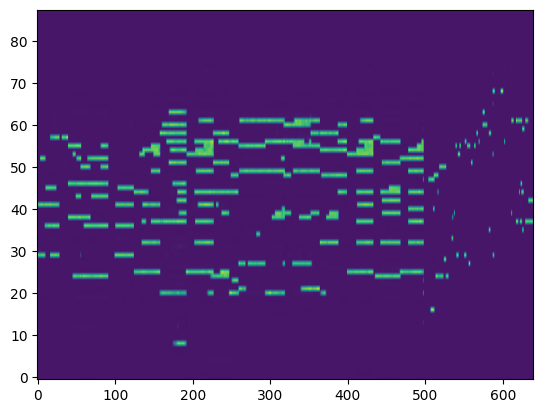
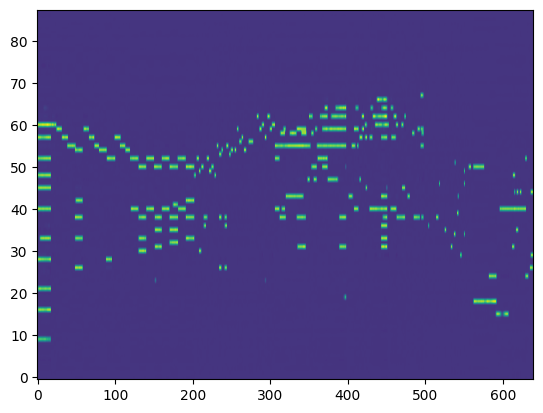
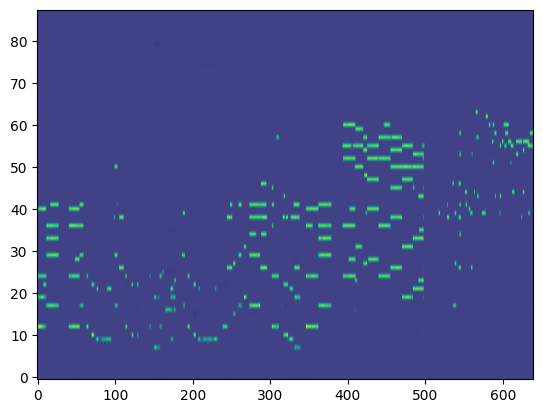
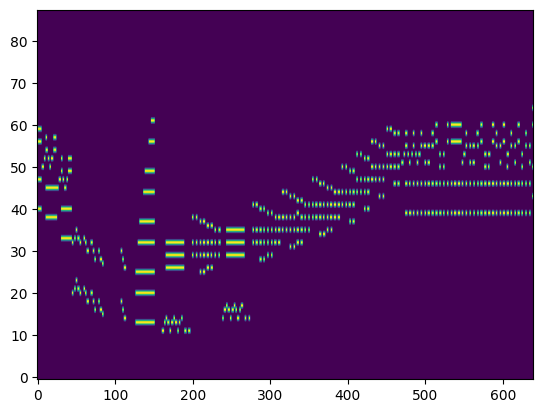
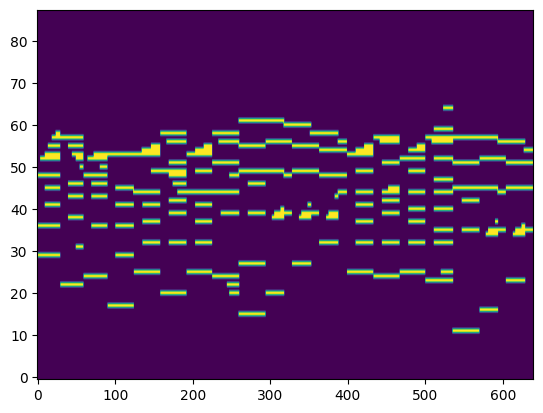
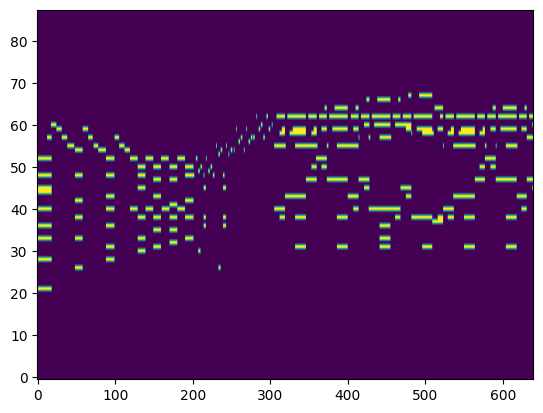
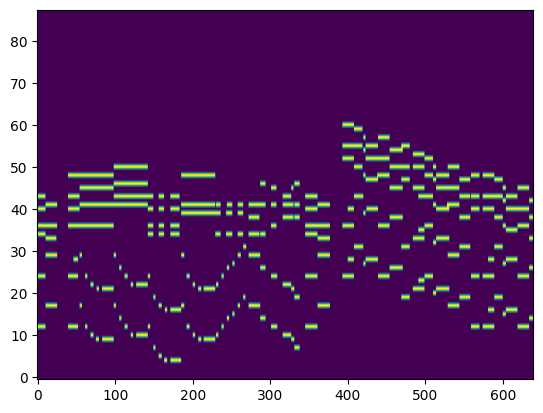
For the transcription, convert the output posteriorgrams into piano rolls and then we export the piano rolls into midi files.
FL Studio is used to synthesize audio from midi files.
| Sampling Trajectory |
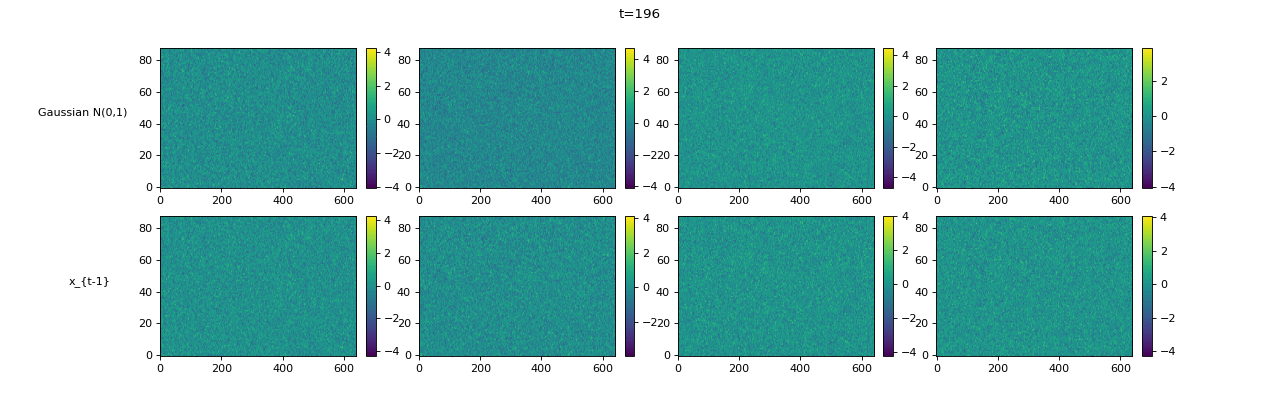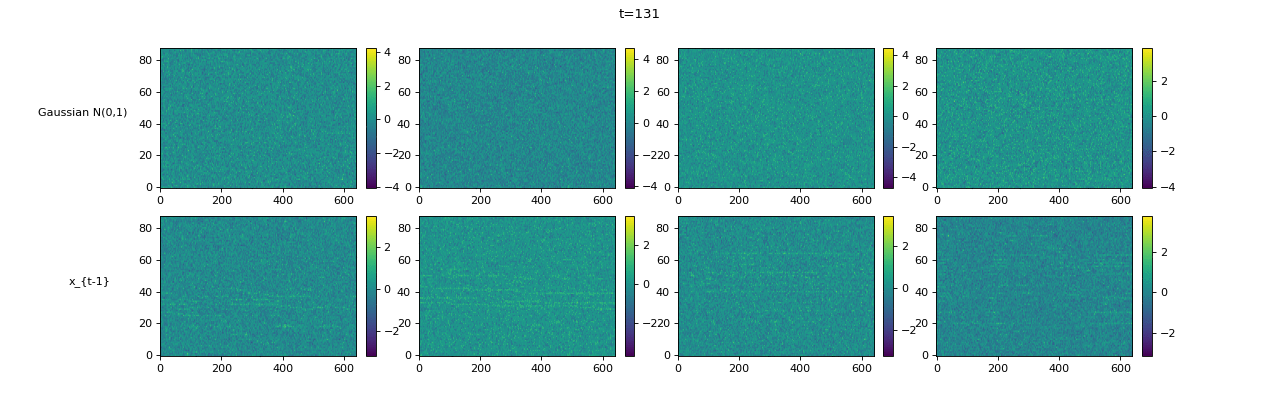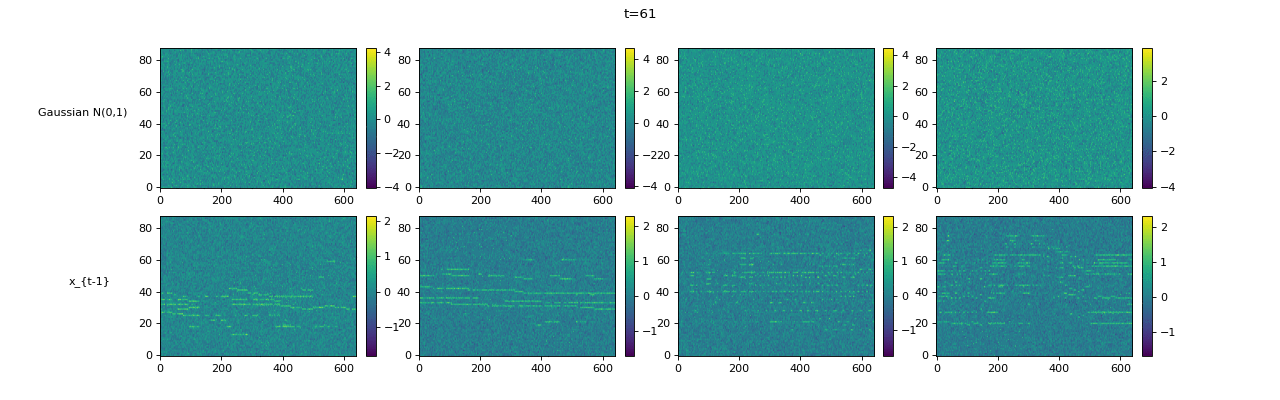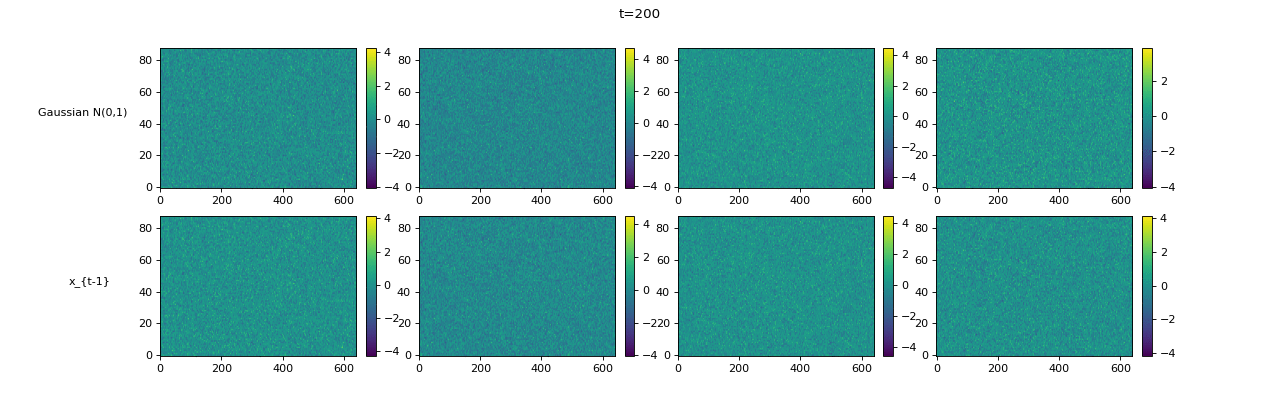 |
|||
| File Name | Sample 1 | Sample 2 | Sample 3 | Sample 4 |
| Input Audio (Condition) | 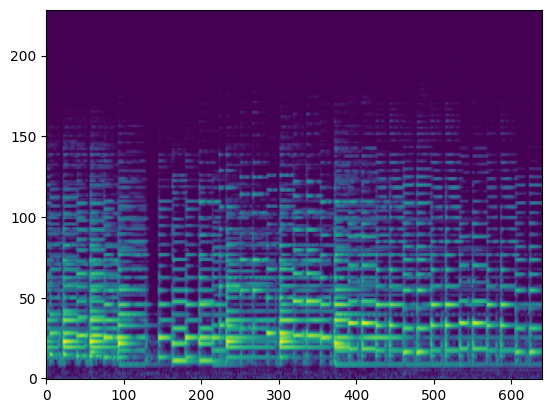 |
 |
 |
 |
| Input Audio (Condition) | ||||
| Transcribed Posteriorgram |
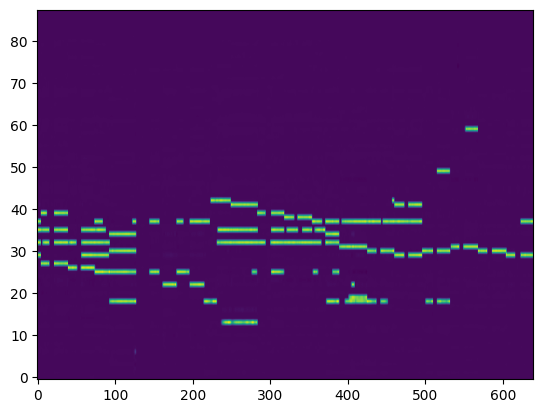 |
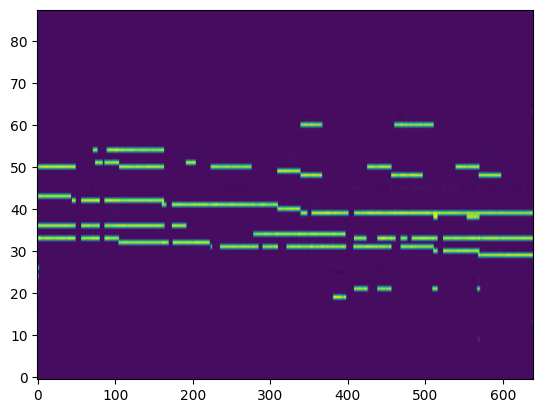 |
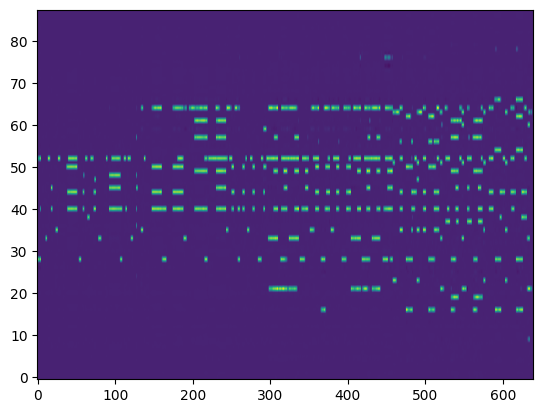 |
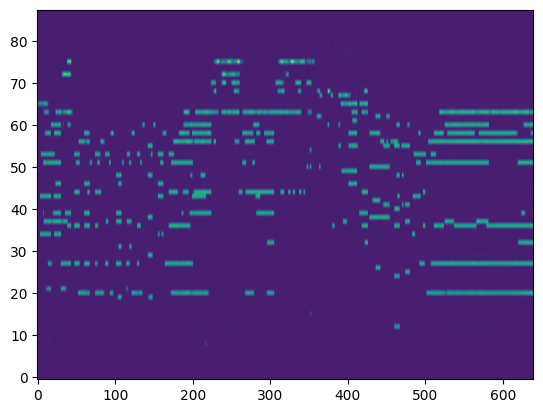 |
| Transcribed MIDI (Synthesized) |
||||
| Output MIDI | Download |
Download |
Download |
Download |
| Ground Truth Piano Roll | 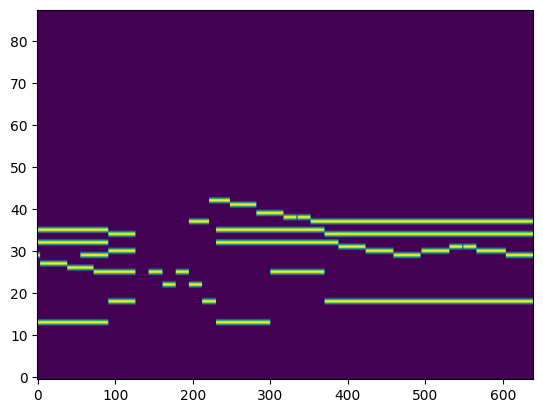 |
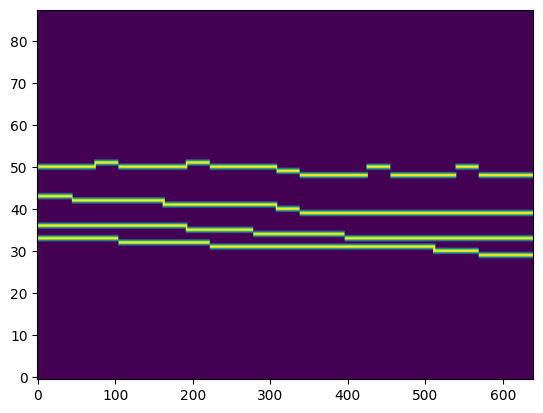 |
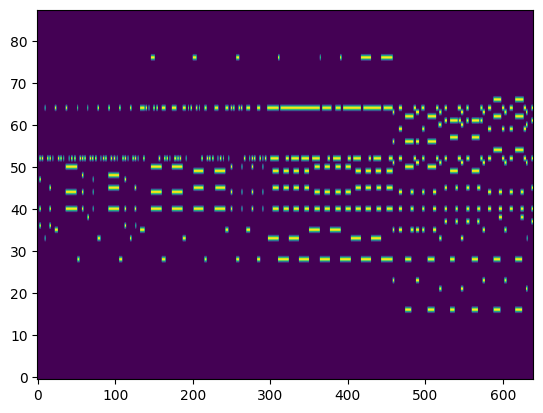 |
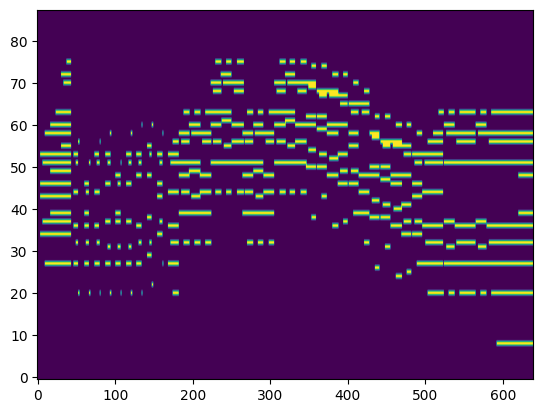 |
| Ground Truth MIDI | ||||