Method
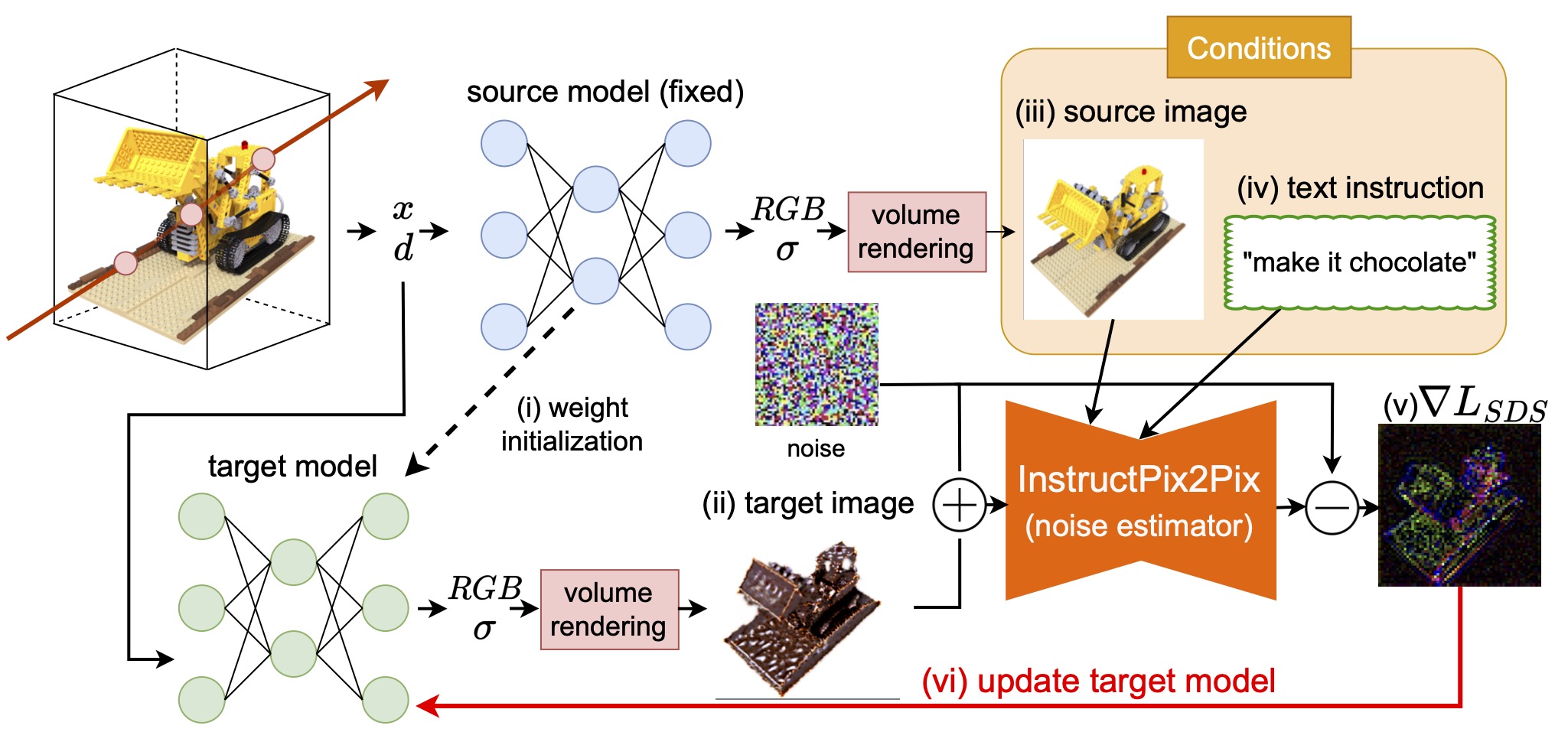
First, the target model is initialized with the source model (i). Next, the target image is rendered from a random camera viewpoint (ii) and then the noise is added to input into InstructPix2Pix. The source image is rendered from the same viewpoint (iii) and input to InstructPix2Pix as conditions along with the text instruction (iv). The gradient of loss function is calculated using them (v) and the target model is updated with it. By performing this procedure from various camera viewpoints, we can convert the target model along with the text instruction.