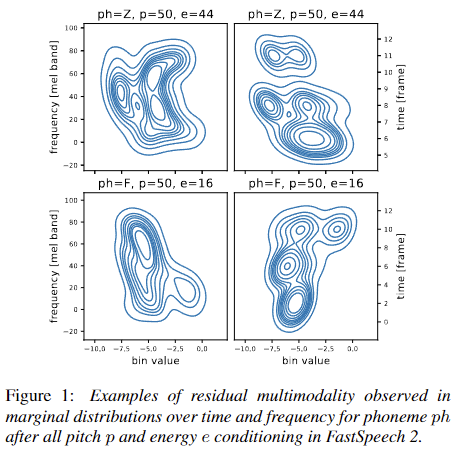
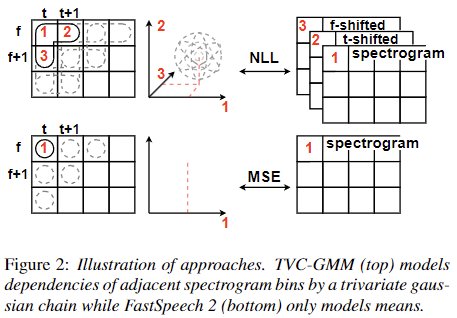
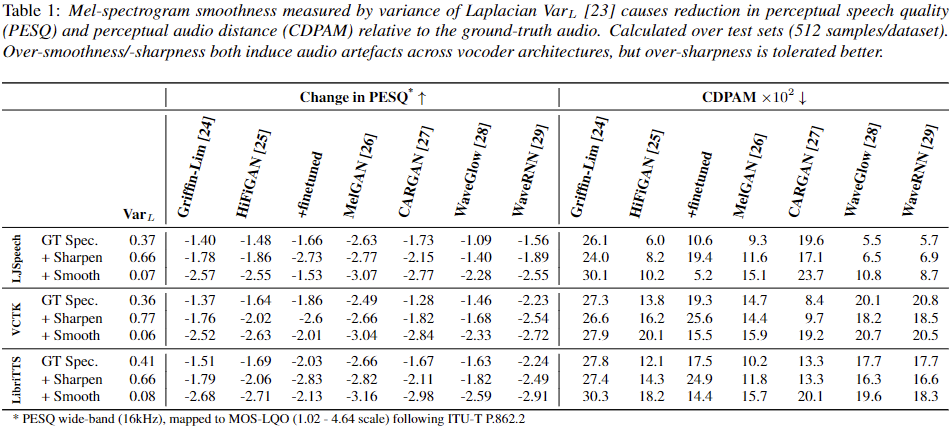
|
Ground-Truth |
Griffin-Lim | HiFiGAN | HiFiGAN (finetuned) | MelGAN | CARGAN | WaveGlow | WaveRNN |
|---|---|---|---|---|---|---|---|
| GT Spectrogram Reconstruction | |||||||
| + Smooth (metallic artefact) | |||||||
| + Sharpen (bubbling artefact) |
|
Ground-Truth |
Griffin-Lim | HiFiGAN | HiFiGAN (finetuned) | MelGAN | CARGAN | WaveGlow | WaveRNN |
|---|---|---|---|---|---|---|---|
| GT Spectrogram Reconstruction | |||||||
| + Smooth (metallic artefact) | |||||||
| + Sharpen (bubbling artefact) |
|
Ground-Truth |
Griffin-Lim | HiFiGAN | HiFiGAN (finetuned) | MelGAN | CARGAN | WaveGlow | WaveRNN |
|---|---|---|---|---|---|---|---|
| GT Spectrogram Reconstruction | |||||||
| + Smooth (metallic artefact) | |||||||
| + Sharpen (bubbling artefact) |
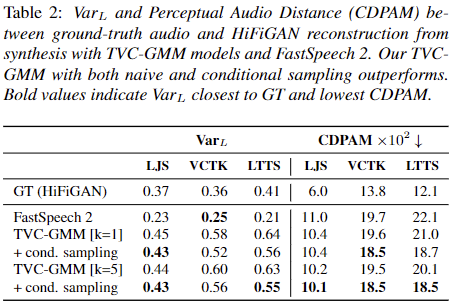
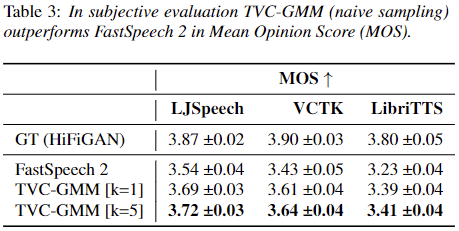
| Ground-Truth | GT Reconstruction (HiFiGAN) | FastSpeech 2 | TVC-GMM [k=1] naive | TVC-GMM [k=5] naive | TVC-GMM [k=1] cond. | TVC-GMM [k=5] cond. | |
|---|---|---|---|---|---|---|---|
| Sample 1 | |||||||
| Sample 2 | |||||||
| Sample 3 | |||||||
| Sample 4 | |||||||
| Sample 5 |
| Ground-Truth | GT Reconstruction (HiFiGAN) | FastSpeech 2 | TVC-GMM [k=1] naive | TVC-GMM [k=5] naive | TVC-GMM [k=1] cond. | TVC-GMM [k=5] cond. | |
|---|---|---|---|---|---|---|---|
| Sample 1 | |||||||
| Sample 2 | |||||||
| Sample 3 | |||||||
| Sample 4 | |||||||
| Sample 5 |
| Ground-Truth | GT Reconstruction (HiFiGAN) | FastSpeech 2 | TVC-GMM [k=1] naive | TVC-GMM [k=5] naive | TVC-GMM [k=1] cond. | TVC-GMM [k=5] cond. | |
|---|---|---|---|---|---|---|---|
| Sample 1 | |||||||
| Sample 2 | |||||||
| Sample 3 | |||||||
| Sample 4 | |||||||
| Sample 5 |