target_platform Module¶
MCT can be configured to quantize and optimize models for different hardware settings. For example, when using qnnpack backend for Pytorch model inference, Pytorch quantization configuration uses per-tensor weights quantization for Conv2d, while when using tflite modeling, Tensorflow uses per-channel weights quantization for Conv2D.
This can be addressed in MCT by using the target_platform module, that can configure different parameters that are hardware-related, and the optimization process will use this to optimize the model accordingly. Models for IMX500, TFLite and qnnpack can be observed here, and can be used using get_target_platform_capabilities function.
Note
For now, some fields of OpQuantizationConfig are ignored during
the optimization process such as quantization_preserving, fixed_scale, and fixed_zero_point.
MCT will use more information from
OpQuantizationConfig, in the future.
The object MCT should get called TargetPlatformCapabilities (or shortly TPC). This diagram demonstrates the main components:
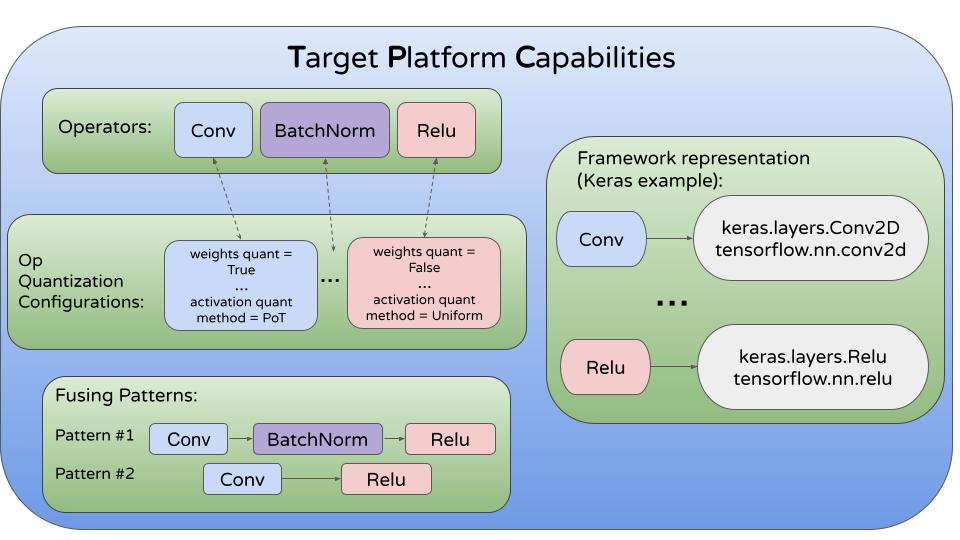
Now, we will detail about the different components.
QuantizationMethod¶
- class model_compression_toolkit.target_platform.QuantizationMethod(value)¶
Method for quantization function selection:
POWER_OF_TWO - Symmetric, uniform, threshold is power of two quantization.
LUT_POT_QUANTIZER - quantization using a lookup table and power of 2 threshold.
SYMMETRIC - Symmetric, uniform, quantization.
UNIFORM - uniform quantization,
LUT_SYM_QUANTIZER - quantization using a lookup table and symmetric threshold.
OpQuantizationConfig¶
- class model_compression_toolkit.target_platform.OpQuantizationConfig(default_weight_attr_config, attr_weights_configs_mapping, activation_quantization_method, activation_n_bits, supported_input_activation_n_bits, enable_activation_quantization, quantization_preserving, fixed_scale, fixed_zero_point, simd_size, signedness)¶
OpQuantizationConfig is a class to configure the quantization parameters of an operator.
- Parameters:
default_weight_attr_config (AttributeQuantizationConfig) – A default attribute quantization configuration for the operation.
attr_weights_configs_mapping (Dict[str, AttributeQuantizationConfig]) – A mapping between an op attribute name and its quantization configuration.
activation_quantization_method (QuantizationMethod) – Which method to use from QuantizationMethod for activation quantization.
activation_n_bits (int) – Number of bits to quantize the activations.
supported_input_activation_n_bits (int or Tuple[int]) – Number of bits that operator accepts as input.
enable_activation_quantization (bool) – Whether to quantize the model activations or not.
quantization_preserving (bool) – Whether quantization parameters should be the same for an operator’s input and output.
fixed_scale (float) – Scale to use for an operator quantization parameters.
fixed_zero_point (int) – Zero-point to use for an operator quantization parameters.
simd_size (int) – Per op integer representing the Single Instruction, Multiple Data (SIMD) width of an operator. It indicates the number of data elements that can be fetched and processed simultaneously in a single instruction.
signedness (bool) – Set activation quantization signedness.
AttributeQuantizationConfig¶
- class model_compression_toolkit.target_platform.AttributeQuantizationConfig(weights_quantization_method=QuantizationMethod.POWER_OF_TWO, weights_n_bits=FLOAT_BITWIDTH, weights_per_channel_threshold=False, enable_weights_quantization=False, lut_values_bitwidth=None)¶
Hold the quantization configuration of a weight attribute of a layer.
Initializes an attribute quantization config.
- Parameters:
weights_quantization_method (QuantizationMethod) – Which method to use from QuantizationMethod for weights quantization.
weights_n_bits (int) – Number of bits to quantize the coefficients.
weights_per_channel_threshold (bool) – Whether to quantize the weights per-channel or not (per-tensor).
enable_weights_quantization (bool) – Whether to quantize the model weights or not.
lut_values_bitwidth (int) – Number of bits to use when quantizing in look-up-table.
QuantizationConfigOptions¶
- class model_compression_toolkit.target_platform.QuantizationConfigOptions(quantization_config_list, base_config=None)¶
Wrap a set of quantization configurations to consider during the quantization of an operator.
- Parameters:
quantization_config_list (List[OpQuantizationConfig]) – List of possible OpQuantizationConfig to gather.
base_config (OpQuantizationConfig) – Fallback OpQuantizationConfig to use when optimizing the model in a non mixed-precision manner.
TargetPlatformModel¶
- class model_compression_toolkit.target_platform.TargetPlatformModel(default_qco, add_metadata=False, name='default_tp_model')¶
Modeling of the hardware the quantized model will use during inference. The model contains definition of operators, quantization configurations of them, and fusing patterns so that multiple operators will be combined into a single operator.
- Parameters:
default_qco (QuantizationConfigOptions) – Default QuantizationConfigOptions to use for operators that their QuantizationConfigOptions are not defined in the model.
add_metadata (bool) – Whether to add metadata to the model or not.
name (str) – Name of the model.
OperatorsSet¶
- class model_compression_toolkit.target_platform.OperatorsSet(name, qc_options=None)¶
Set of operators that are represented by a unique label.
- Parameters:
name (str) – Set’s label (must be unique in a TargetPlatformModel).
qc_options (QuantizationConfigOptions) – Configuration options to use for this set of operations.
Fusing¶
- class model_compression_toolkit.target_platform.Fusing(operator_groups_list, name=None)¶
Fusing defines a list of operators that should be combined and treated as a single operator, hence no quantization is applied between them.
- Parameters:
operator_groups_list (List[Union[OperatorsSet, OperatorSetConcat]]) – A list of operator groups, each being either an OperatorSetConcat or an OperatorsSet.
name (str) – The name for the Fusing instance. If not provided, it’s generated from the operator groups’ names.
OperatorSetConcat¶
- class model_compression_toolkit.target_platform.OperatorSetConcat(*opsets)¶
Concatenate a list of operator sets to treat them similarly in different places (like fusing).
Group a list of operation sets.
- Parameters:
*opsets (OperatorsSet) – List of operator sets to group.
OperationsToLayers¶
- class model_compression_toolkit.target_platform.OperationsToLayers(op_sets_to_layers=None)¶
Gather multiple OperationsSetToLayers to represent mapping of framework’s layers to TargetPlatformModel OperatorsSet.
- Parameters:
op_sets_to_layers (List[OperationsSetToLayers]) – List of OperationsSetToLayers where each of them maps an OperatorsSet name to a list of layers that represents the OperatorsSet.
OperationsSetToLayers¶
- class model_compression_toolkit.target_platform.OperationsSetToLayers(op_set_name, layers, attr_mapping=None)¶
Associate an OperatorsSet to a list of framework’s layers.
- Parameters:
op_set_name (str) – Name of OperatorsSet to associate with layers.
layers (List[Any]) – List of layers/FilterLayerParams to associate with OperatorsSet.
attr_mapping (Dict[str, DefaultDict]) – A mapping between a general attribute name to a DefaultDict that maps a layer type to the layer’s framework name of this attribute.
LayerFilterParams¶
- class model_compression_toolkit.target_platform.LayerFilterParams(layer, *conditions, **kwargs)¶
Wrap a layer with filters to filter framework’s layers by their attributes.
- Parameters:
layer – Layer to match when filtering.
*conditions (AttributeFilter) – List of conditions to satisfy.
**kwargs – Keyword arguments to filter layers according to.
More filters and usage examples are detailed here.
TargetPlatformCapabilities¶
- class model_compression_toolkit.target_platform.TargetPlatformCapabilities(tp_model, name='base', version=None)¶
Attach framework information to a modeled hardware.
- Parameters:
tp_model (TargetPlatformModel) – Modeled hardware to attach framework information to.
name (str) – Name of the TargetPlatformCapabilities.
version (str) – TPC version.