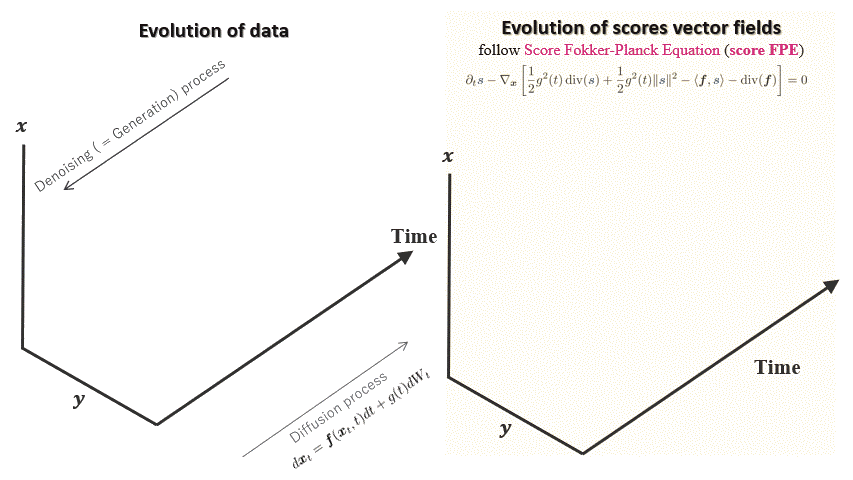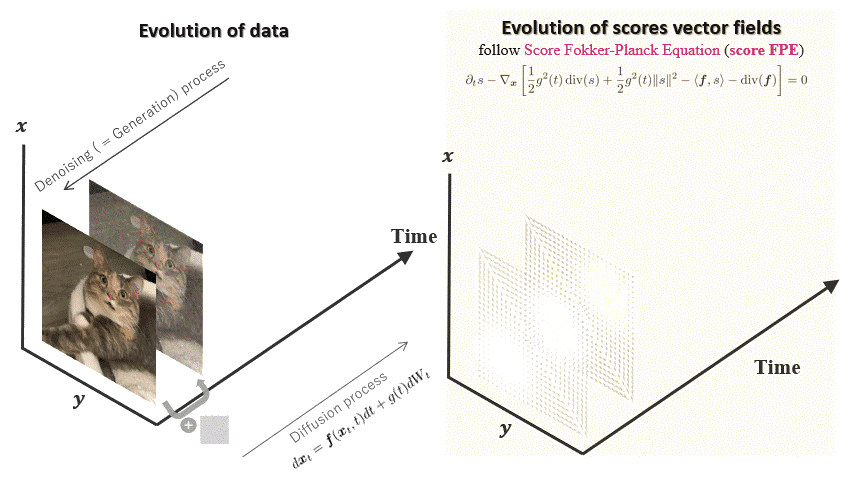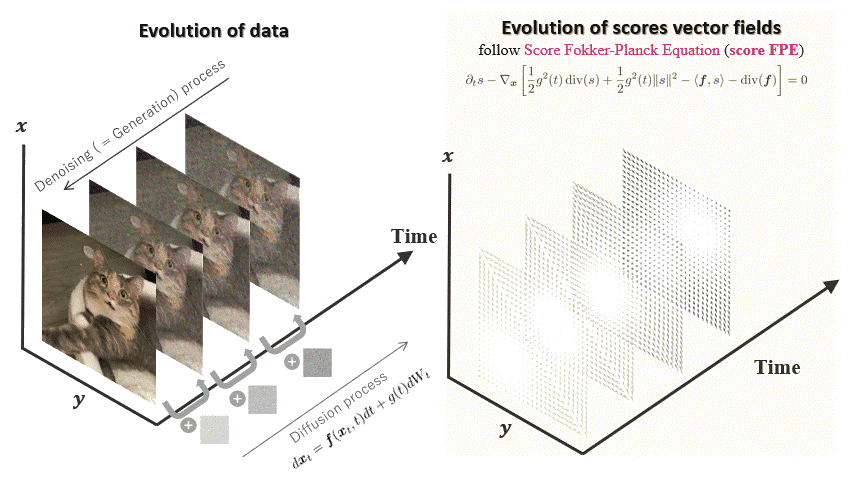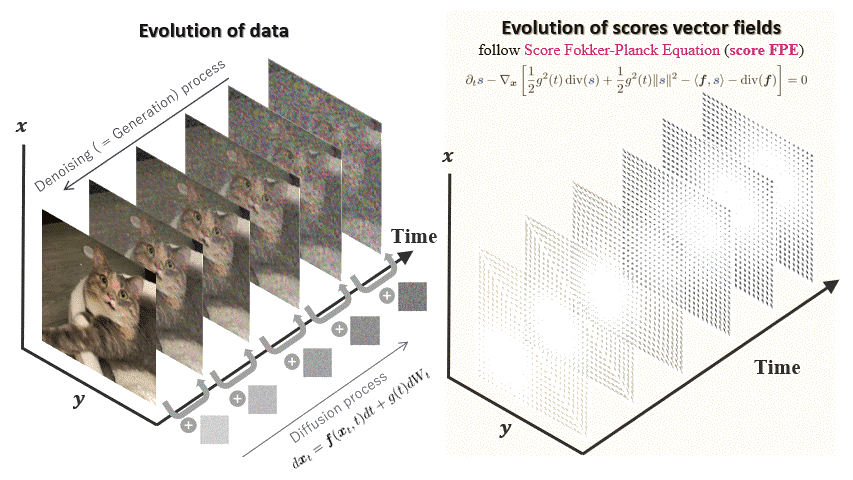
Deep Generative Modeling
LACU
[arXiv]
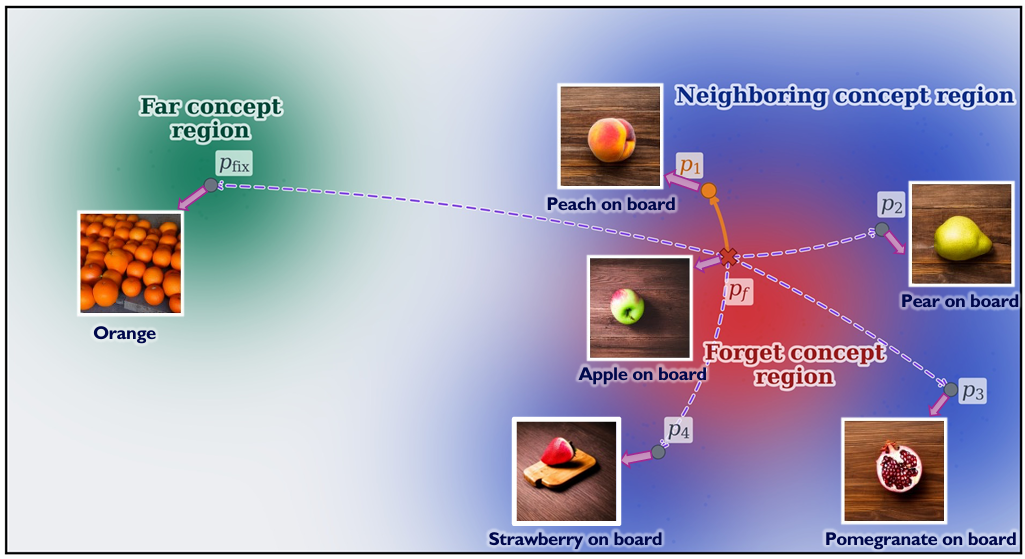
Locality-aware continual unlearning (LACU), a framework that stabilizes sequential concept removal
GUDA
[arXiv]
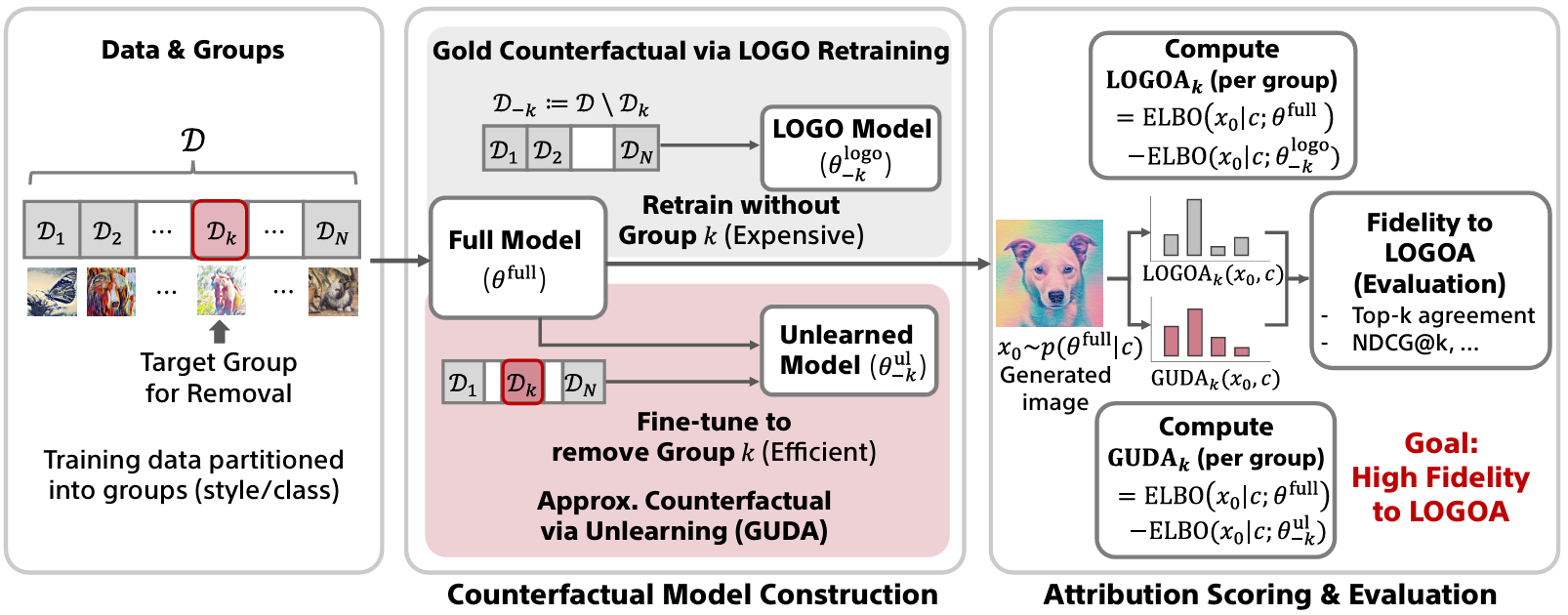
Efficiently estimate which training data groups influenced diffusion model outputs
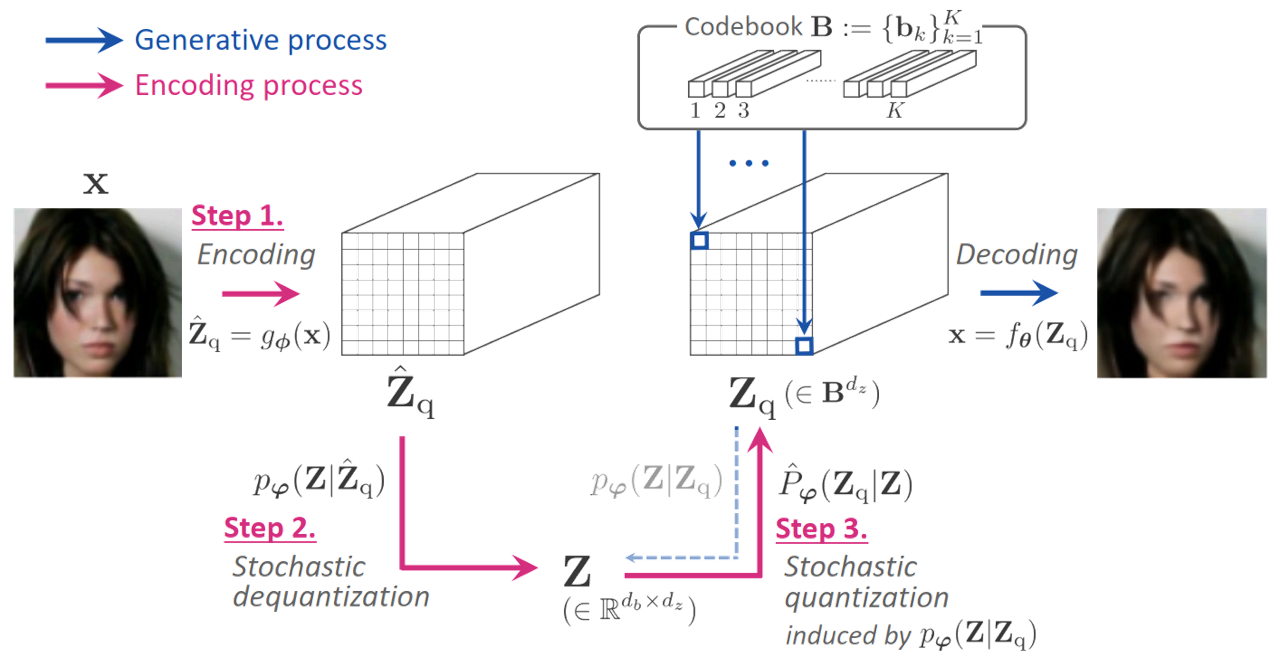
Demystifying MaskGIT
[arXiv]
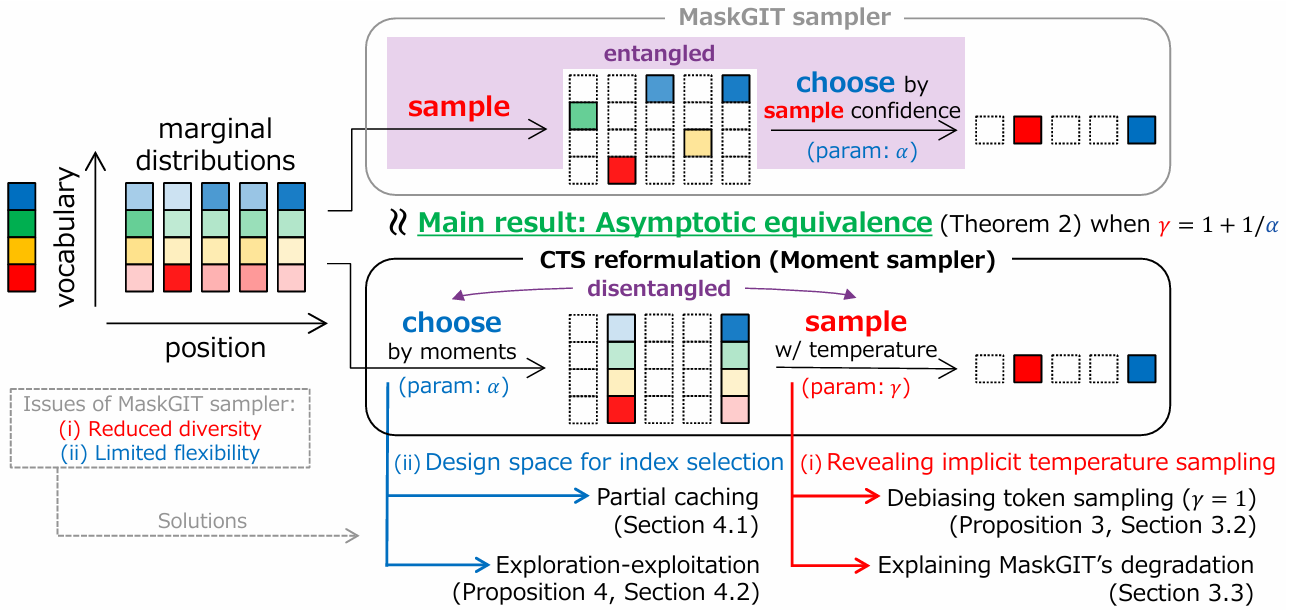
Theoretically analyzes the MaskGIT sampler, poviding a choose-then-sample (CTS) formulation
MF-RAE

[arXiv]
Training flow-map models in RAE latent with consistency mid-training for trajectory-aware initialization
ConceptTRAK
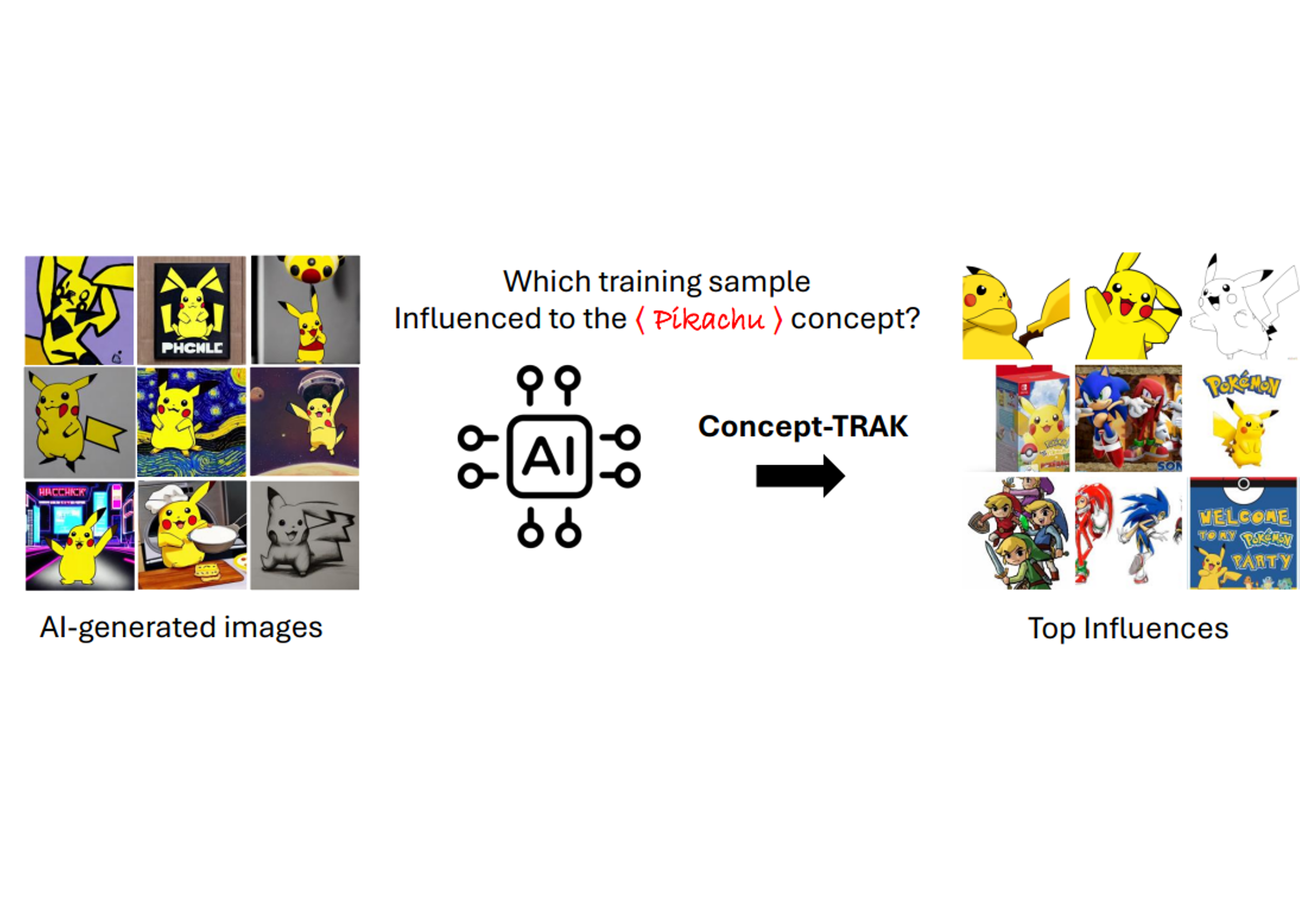
[arXiv]
A framework for Identify which training examples influenced specific concepts within the diffusion model
CMT
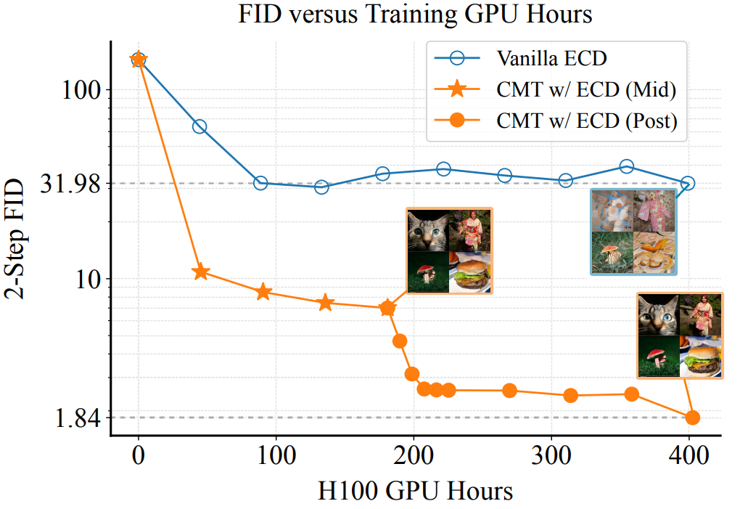
[arXiv]
CMT reduces the training cost of diffusion-based flow map models by up to 90% while reaching SOTA performance
CODA
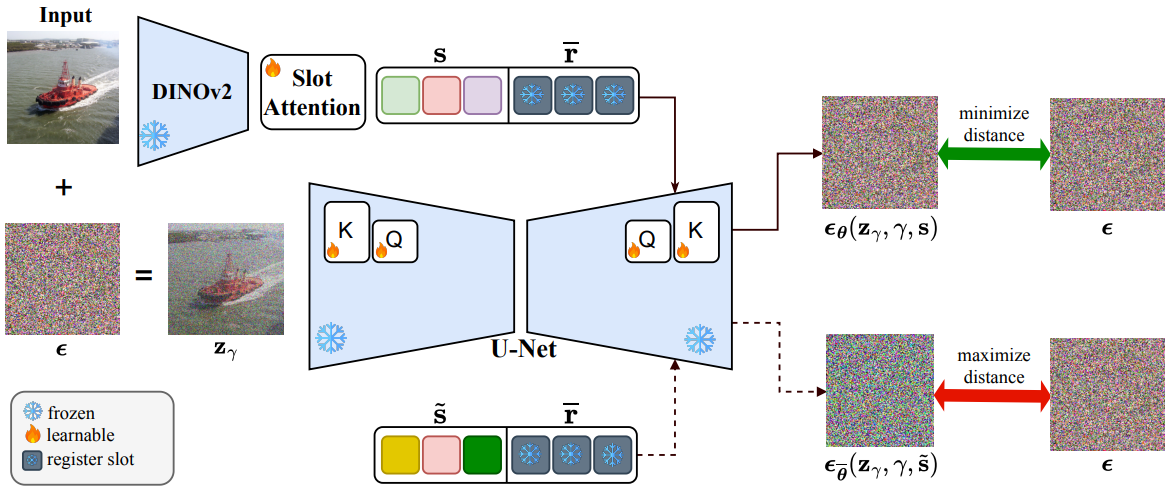
[arXiv]
Improved object-centric diffusion learning with registers and contrastive alignment
Improved CFG

[arXiv]
An improved mechanism for applying classifier-free guidance in discrete diffusion
SONA
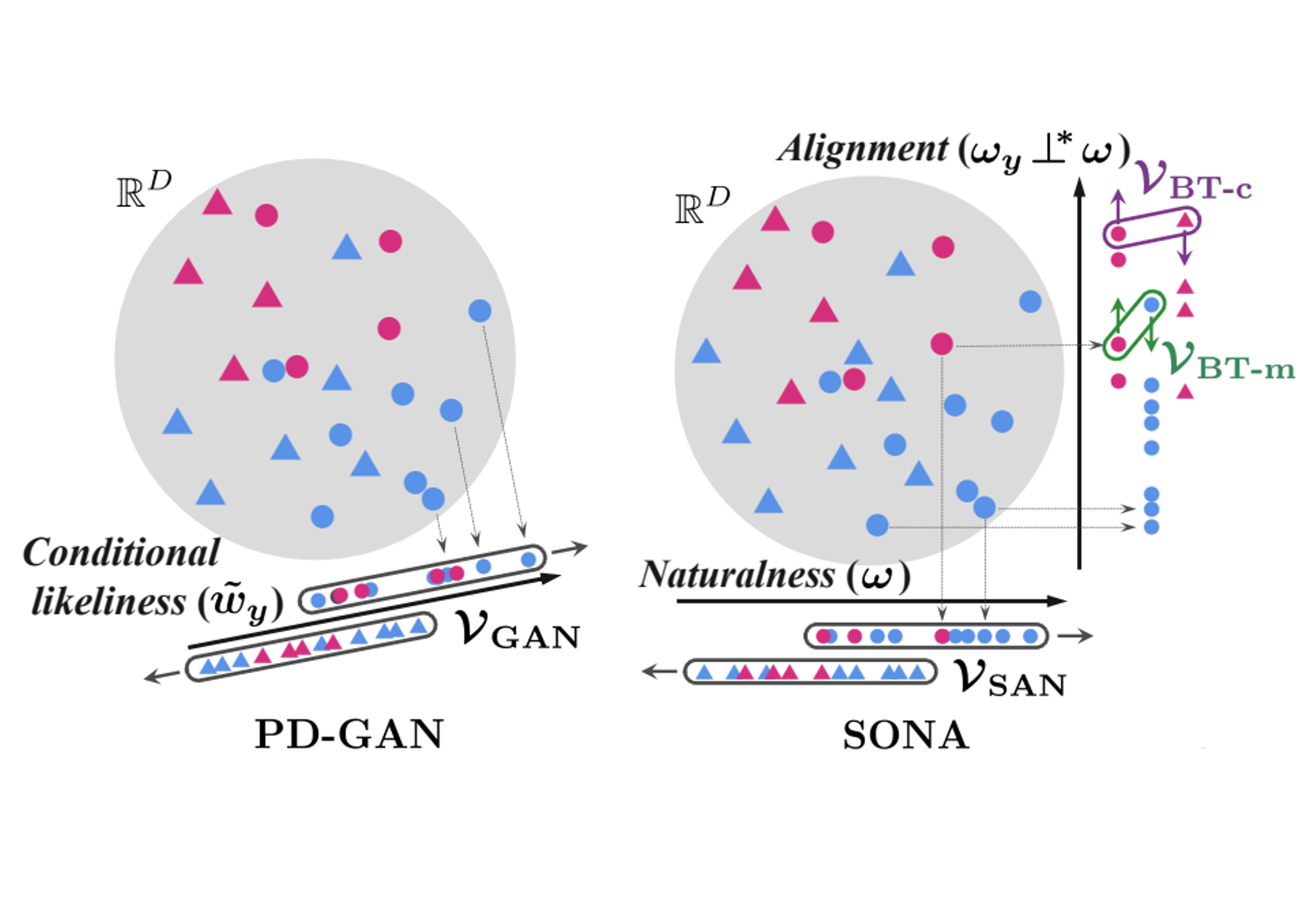
[arXiv]
Learning conditional, unconditional, and matching-aware discriminator with adaptive weighting mechanism (cSAN)
G2D2
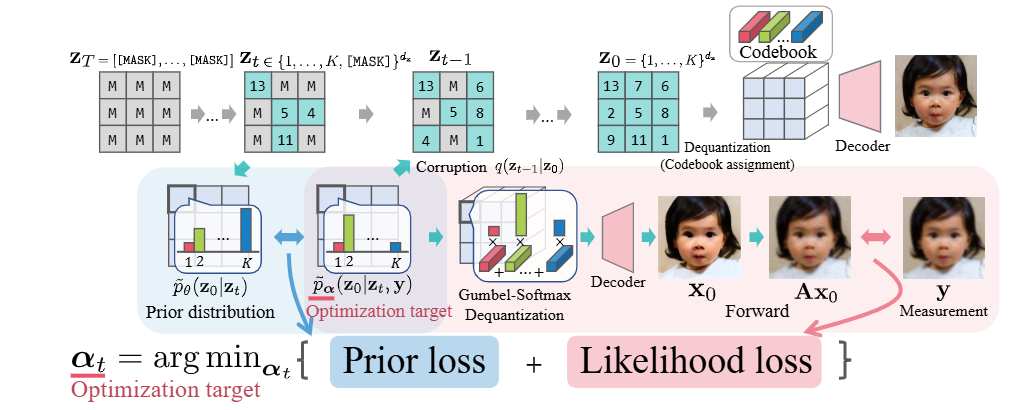
[arXiv]
Leveraging discrete diffusion models as priors for inverse problems
TLoRA

[arXiv]
Propose tensor-decomposition-based PEFT method, showing its effectiveness on T-to-I generation tasks
Di4C
[arXiv] [code]
Theoretical analysis of limitation of current discrete diffusion and a method for effectively capturing element-wise dependency
Memorization
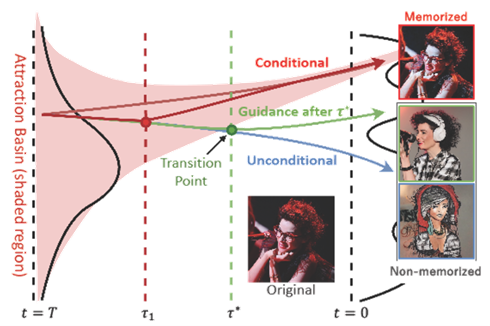
[arXiv] [code]
Classifier-Free Guidance inside the Attraction Basin May Cause Memorization
Jump Your Steps
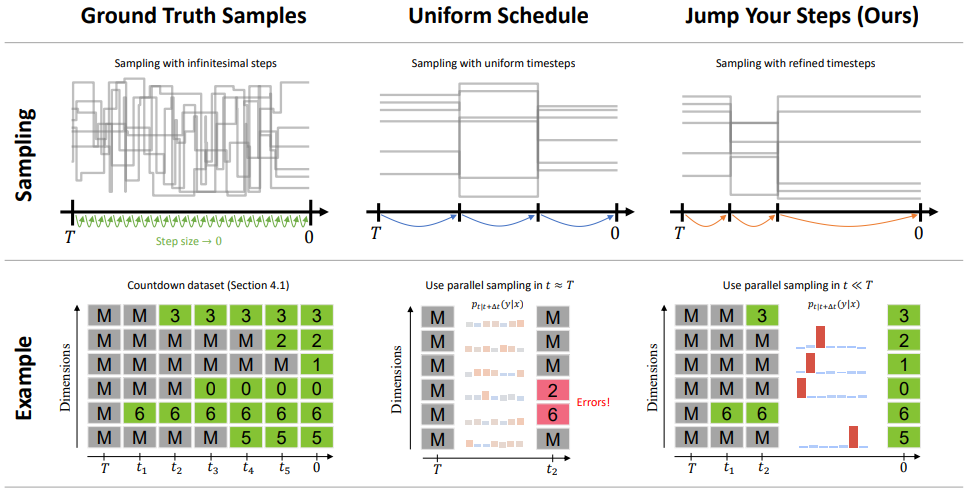
[arXiv]
A general method to find an optimal sampling schedule for inference in discrete diffusion
HERO-DM

[arXiv] [demo]
A method efficiently leverages online human feedback to fine-tune Stable Diffusion for various range of tasks
WPSE
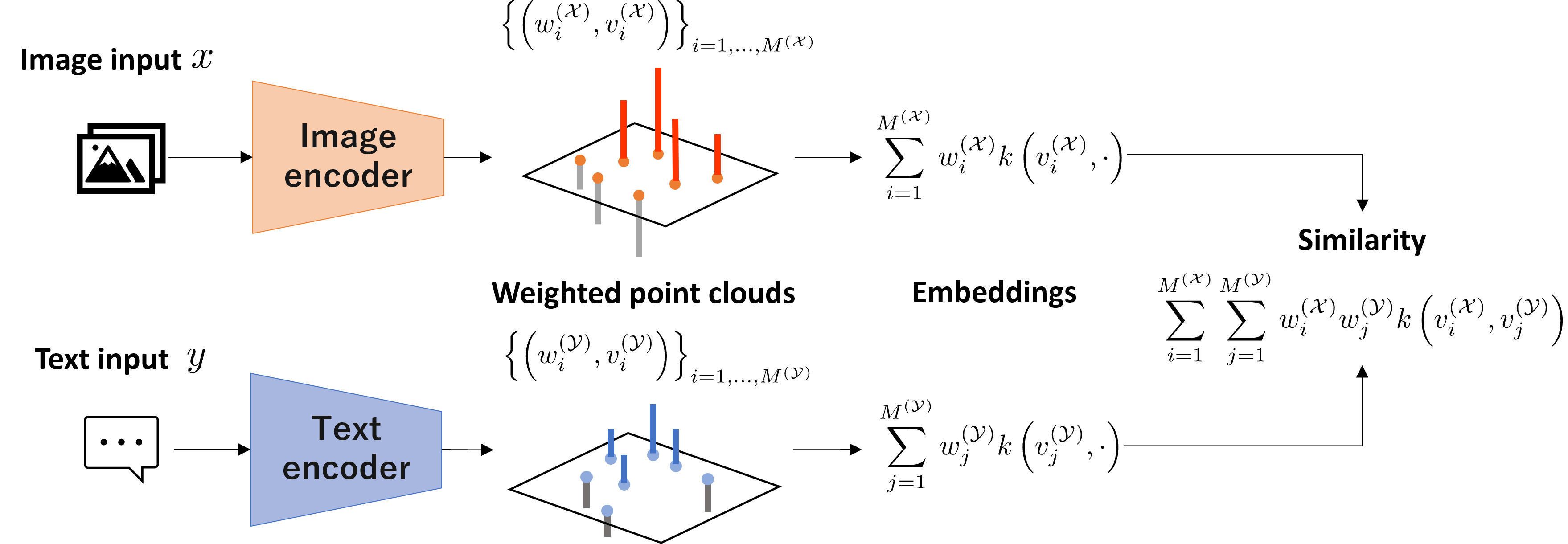
[arXiv]
An enhanced multimodal representation using weighted point clouds and its theoretical benefits
PaGoDA

[arXiv]
A 64x64 pre-trained diffusion model is all you need for 1-step high-resolution SOTA generation
CTM

[arXiv] [demo]
Unified framework enables diverse samplers and 1-step generation SOTAs
Applications:
[SoundGen]
SAN
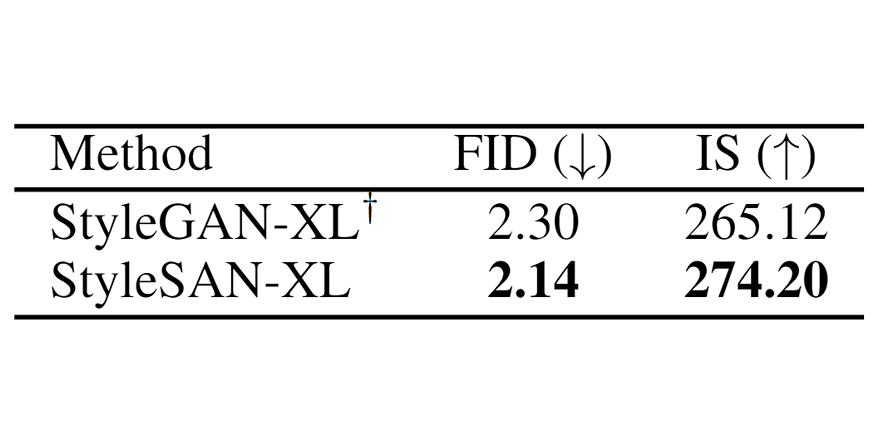
[arXiv] [code] [demo]
Enhancing GAN with metrizable discriminators
Applications:
[Vocoder]
MPGD

[arXiv] [demo]
Fast, Efficient, Training-Free, and Controllable diffusion-based generation method
GibbsDDRM

[PMLR] [code]
Achieving blind inversion using DDPM
Applications:
[DeReverb]
[SpeechEnhance]

Multimodal NLP
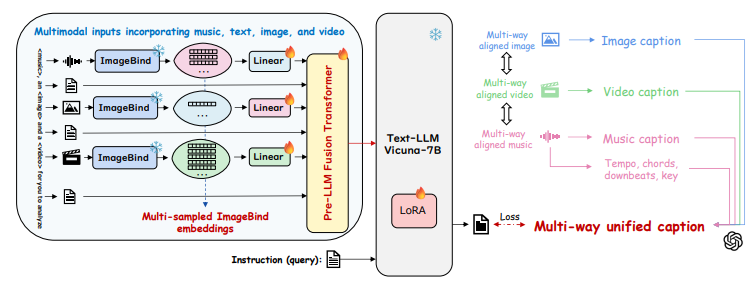
DeepResonance
[EMNLP] [arXiv] [code]
DeepResonance: Enhancing Multimodal Music Understanding via Music-centric Multi-way Instruction Tuning
CARE

[EMNLP] [arXiv] [data]
CARE: Assessing the Impact of Multilingual Human Preference Learning on Cultural Awareness
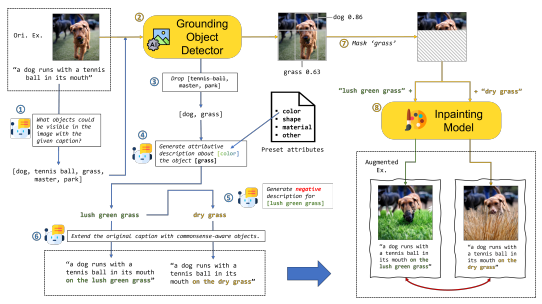
BiAug
[MRR@ICCV25] [arXiv]
Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association
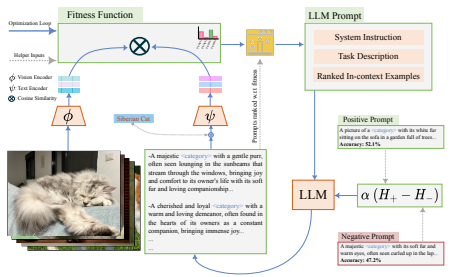
GLOV
[TMLR] [arXiv]
GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
Music-to-MVD
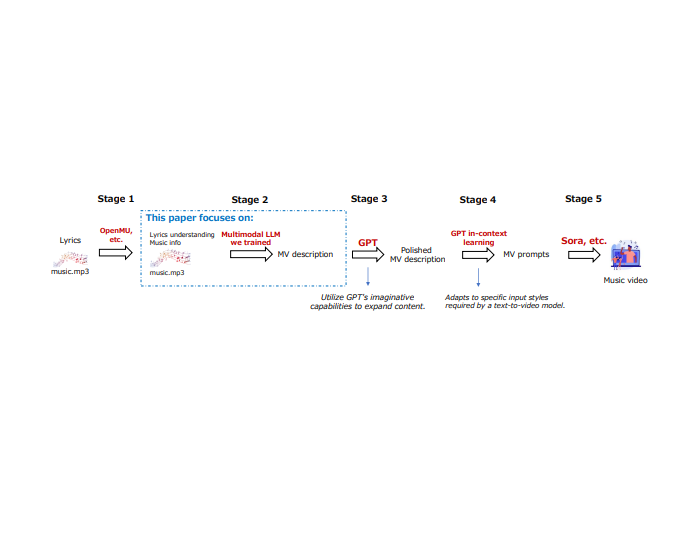
[RepL4NLP@NAACL25] [arXiv]
Cross-Modal Learning for Music-to-Music-Video Description Generation
VinaBench
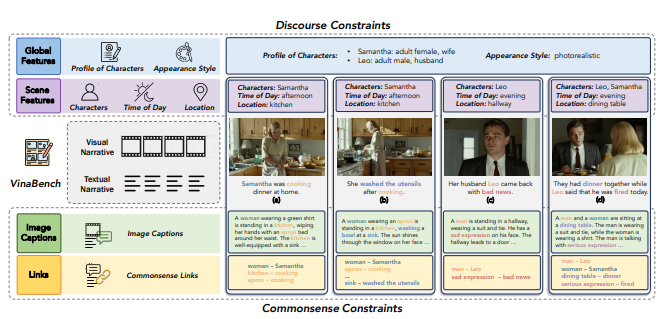
[CVPR] [arXiv] [data]
VinaBench: Benchmark for Faithful and Consistent Visual Narratives
OpenMU
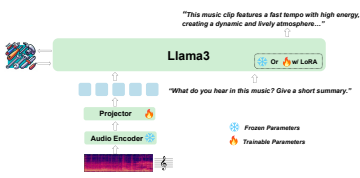
[arXiv] [data] [demo]
OpenMU: Your Swiss Army Knife for Music Understanding

DIIR
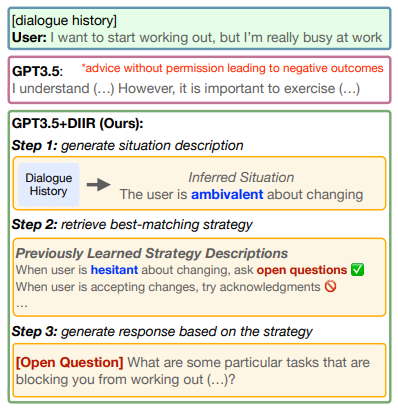
[ACL] [arXiv] [code]
Few-shot Dialogue Strategy Learning for Motivational Interviewing via Inductive Reasoning
Music Technologies
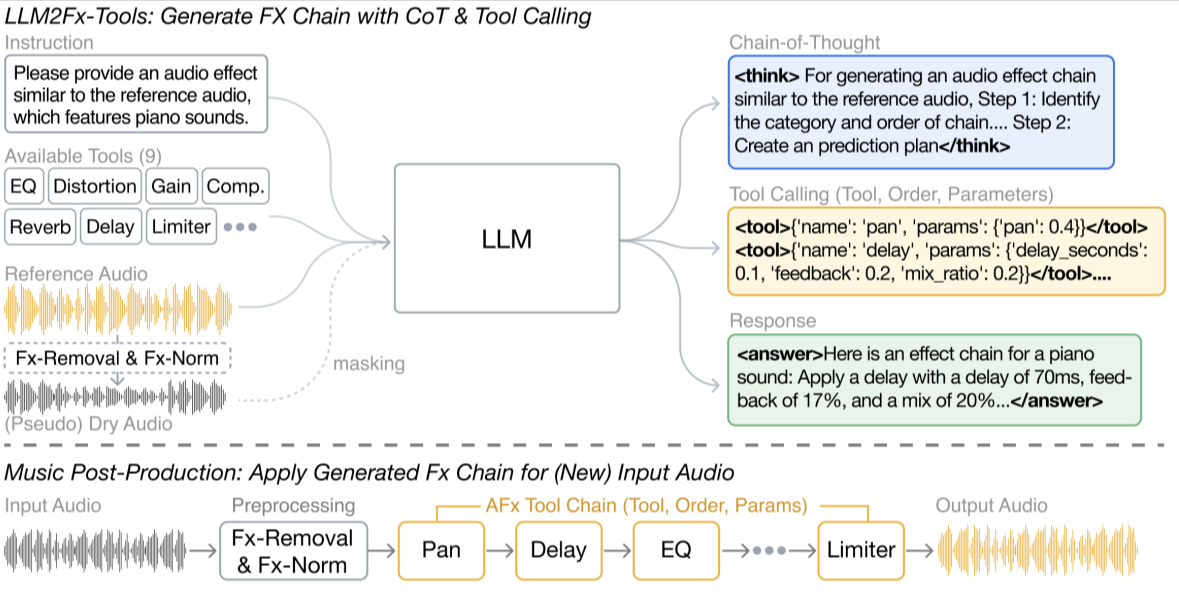
MEGAMI
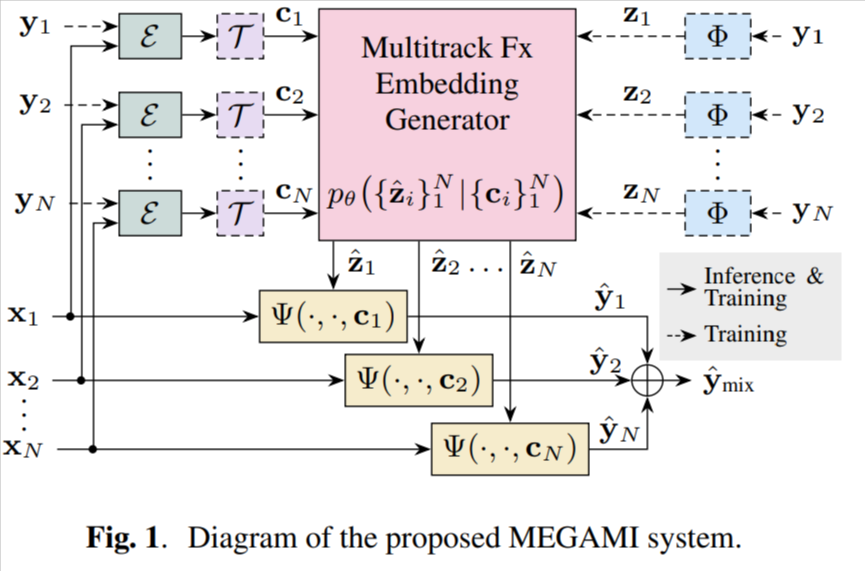
[arXiv] [code] [demo]
Automatic music mixing using a generative model of effect embeddings
Sampling Identification
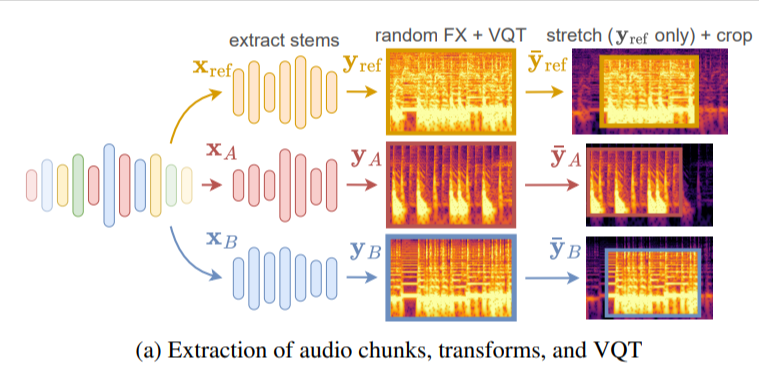
[arXiv] [code]
Automatic Music Sample Identification with Multi-Track Contrastive Learning
Lyrics Matching
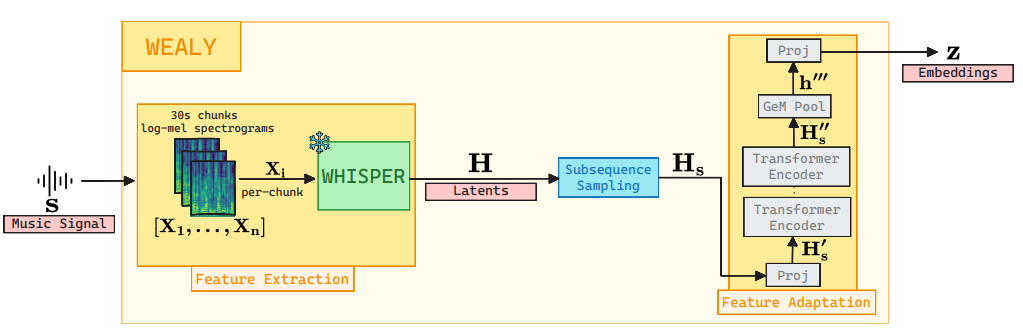
[arXiv] [code]
Leveraging Whisper Embeddings for Audio-based Lyrics Matching
Training Data Attribution
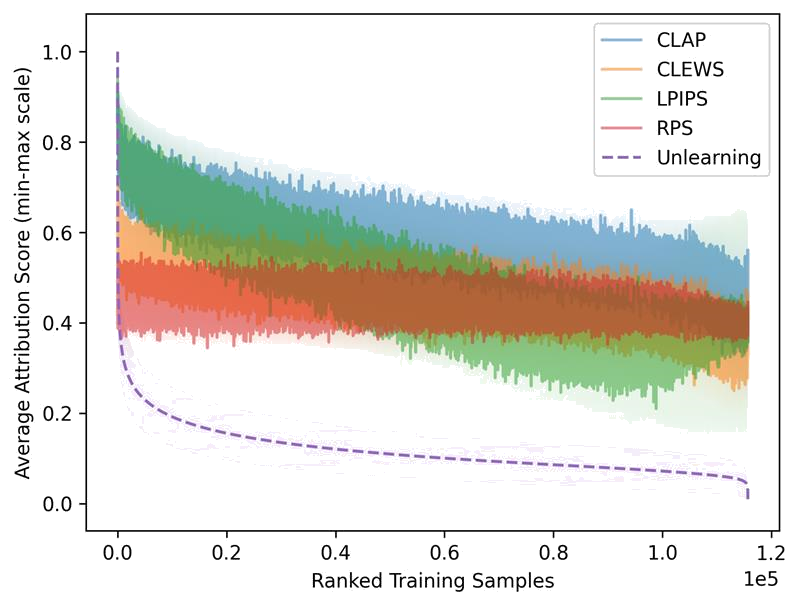
[arXiv]
Large-Scale Training Data Attribution for Music Generative Models via Unlearning
Beyond GenAI Music

[url]
Reductive, exclusionary, normalising: The limits of generative AI music
LLM2FX
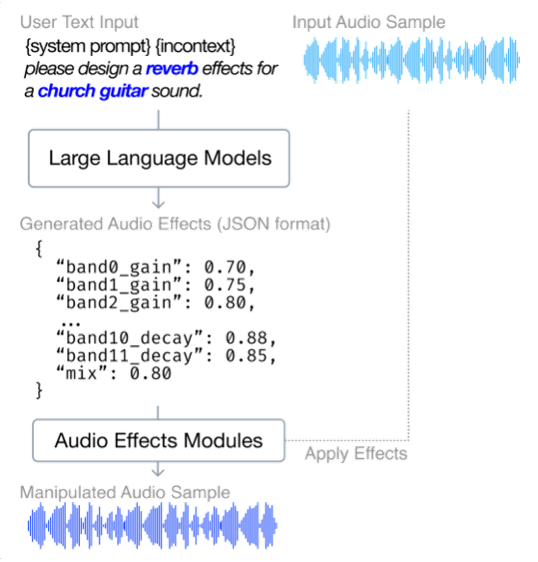
[arXiv] [code] [demo] [dataset]
Can Large Language Models Predict Audio Effects Parameters from Natural Language?
Vocal Effects Style Transfer
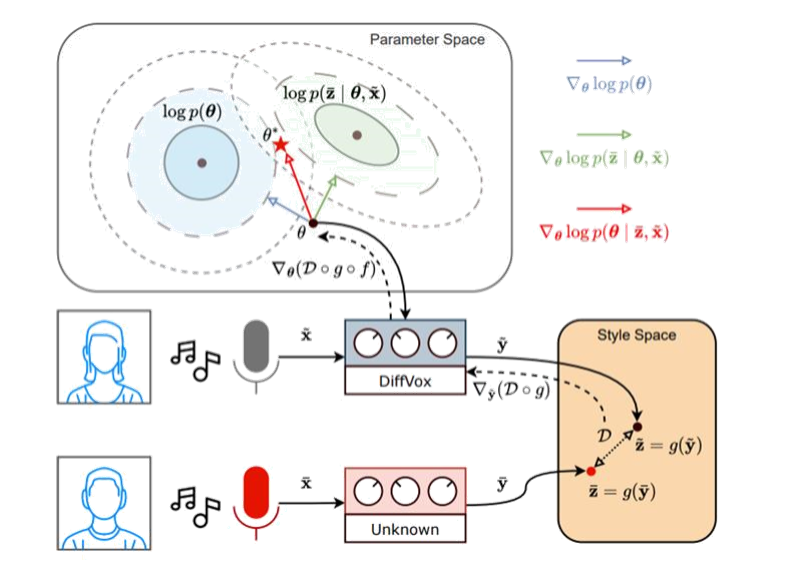
[arXiv] [code] [demo]
Inference-Time Optimisation for Vocal Effects Style Transfer using DiffVox
Fx-Encoder++
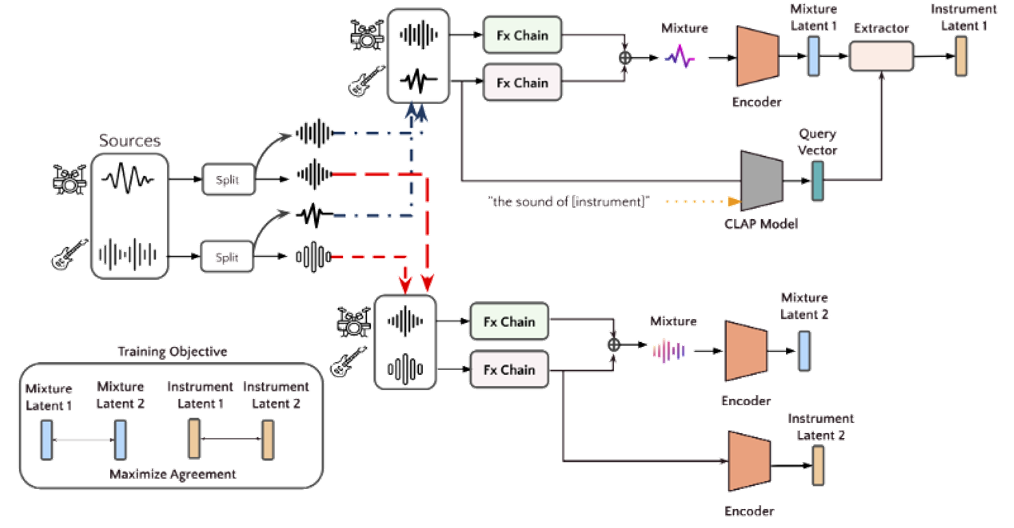
[arXiv] [code]
SOTA Fx representation: Extract instrument-wise audio effects representations from music mixtures
ITO-Master
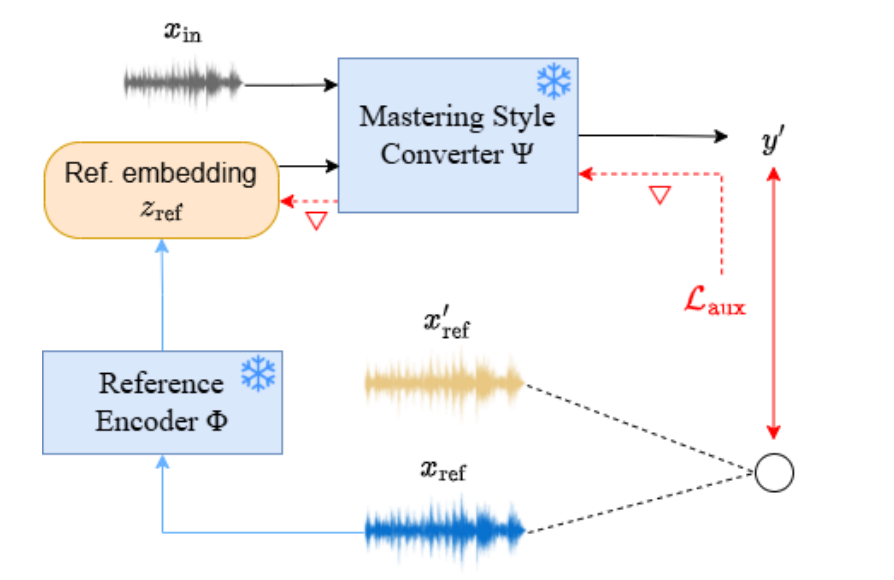
[arXiv] [code] [demo]
Inference Time Optimization for Music Mastering Style Transfer
GRAFx (ext.)
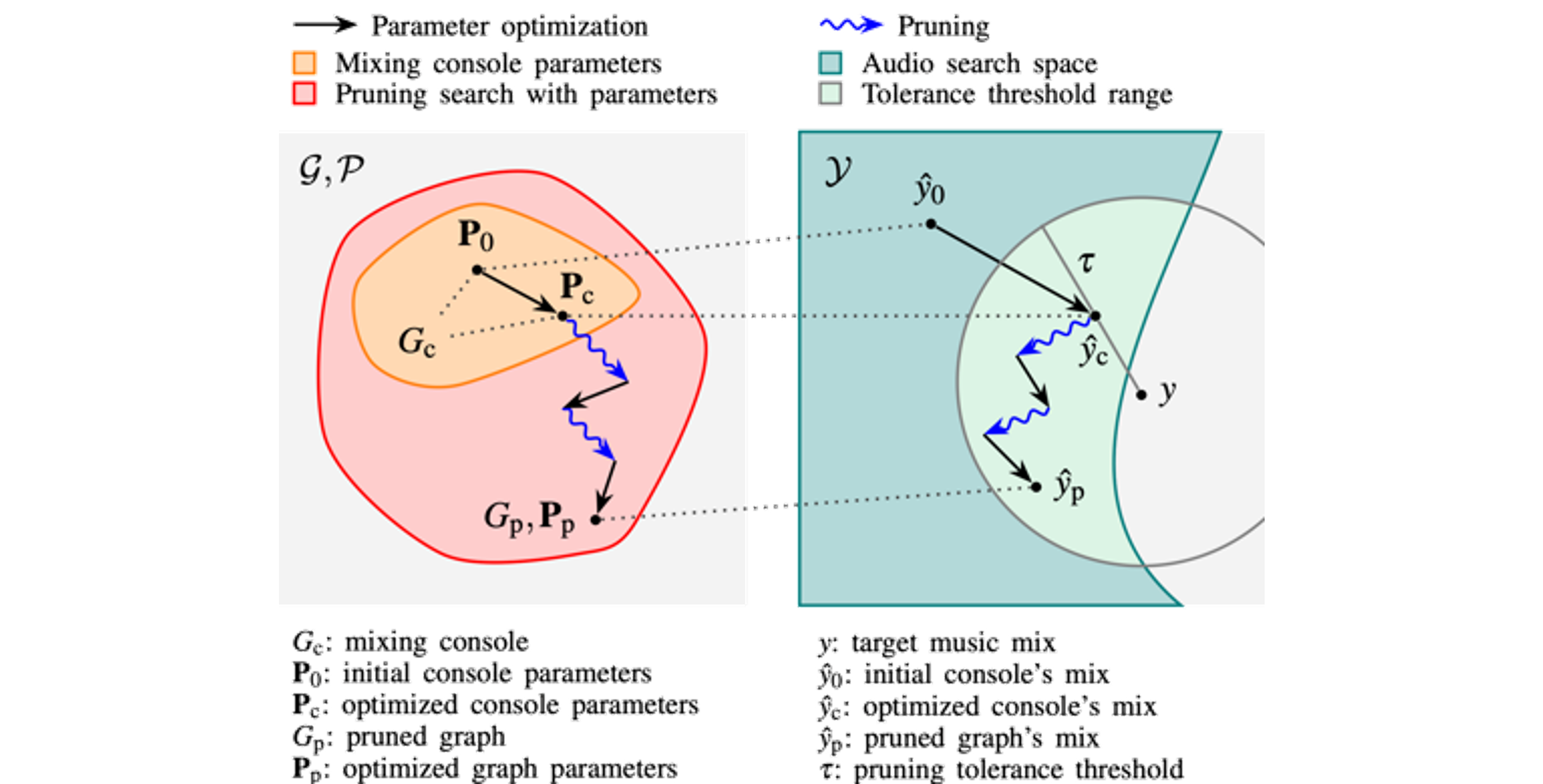
[JAES] [code] [demo]
Reverse Engineering of Music Mixing Graphs with Differentiable Processors and Iterative Pruning
CLEWS

[arXiv]
Supervised contrastive learning from weakly-labeled audio segments for musical version matching
MFM as Generic Booster
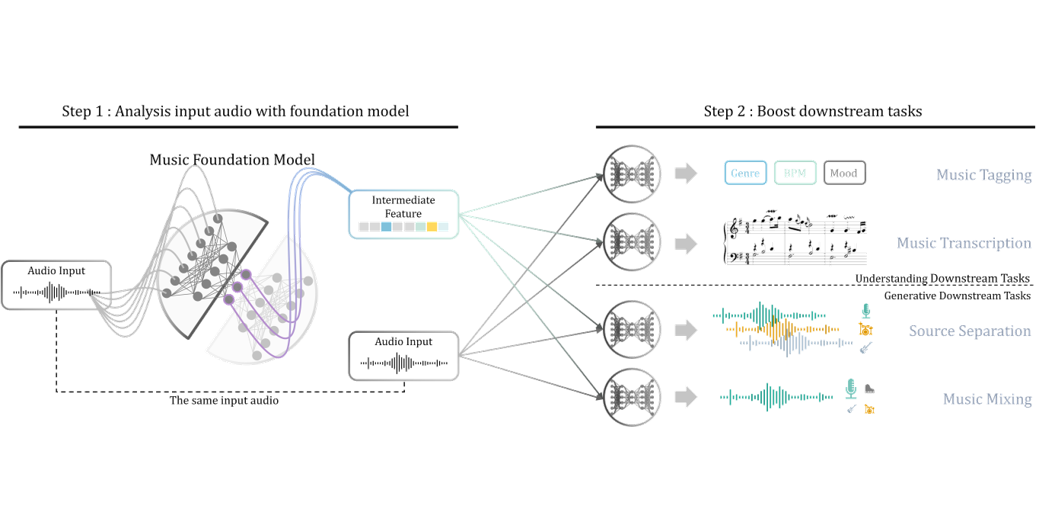
[OpenReview] [arXiv]
Music Foundation Model as Generic Booster for Music Downstream Tasks
DiffVox
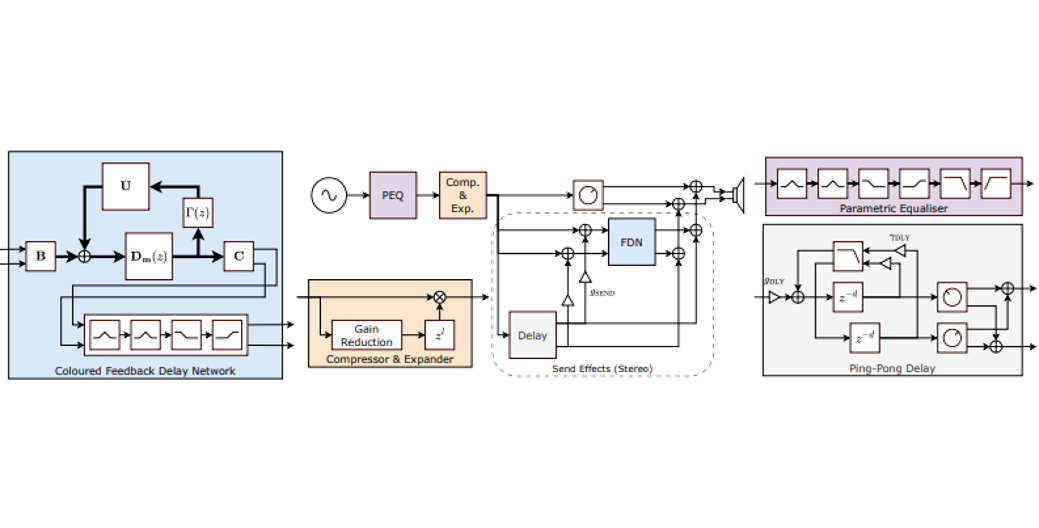
[arXiv] [code] [demo] [audio]
DiffVox: A Differentiable Model for Capturing and Analysing Professional Effects Distributions
Variable Bitrate RVQ
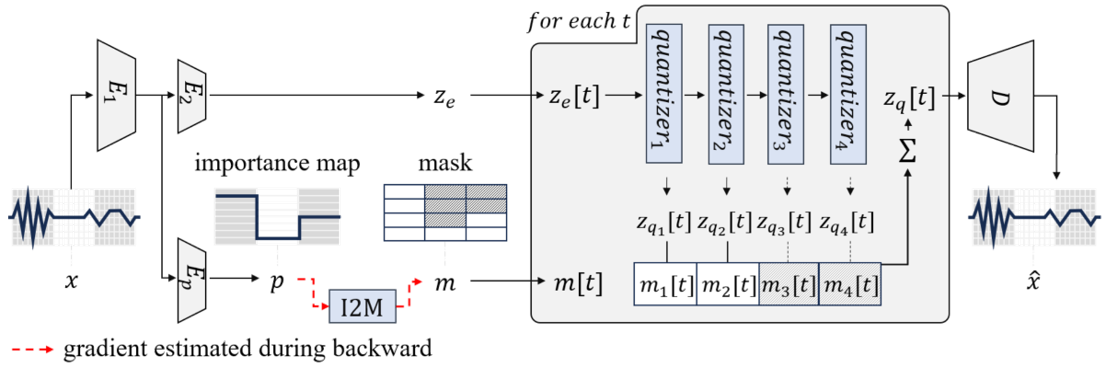
[arXiv]
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Instr. Timbre Transfer
[arXiv] [code] [demo]
Latent Diffusion Bridges for Unsupervised Musical Audio Timbre Transfer
Mixing Graph Estimation
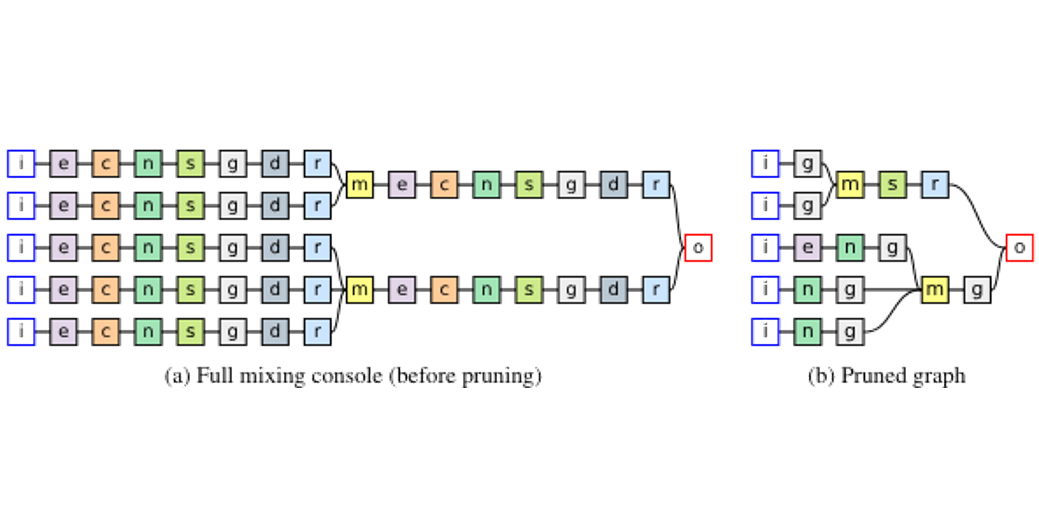
[arXiv] [code] [demo]
Searching For Music Mixing Graphs: A Pruning Approach
Guitar Amp. Modeling
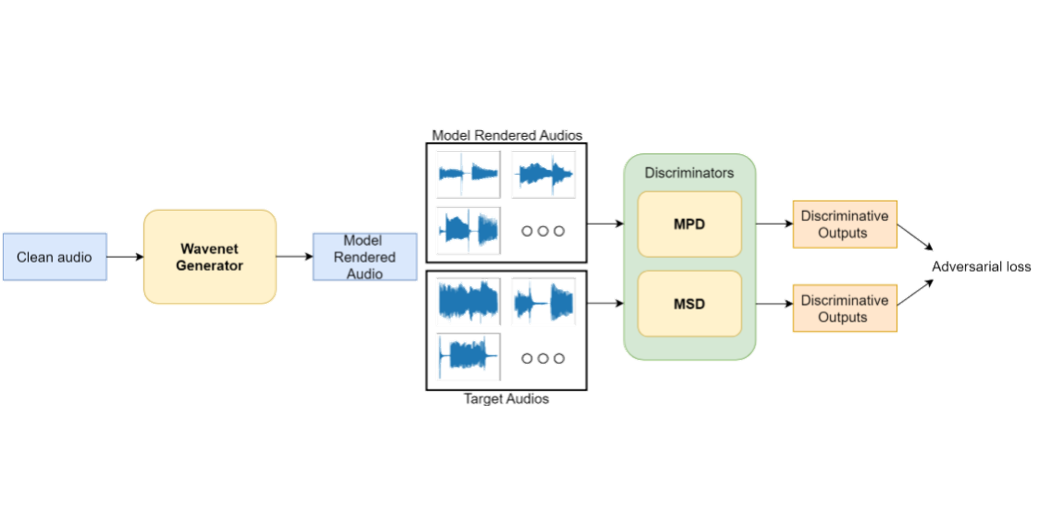
[arXiv]
Improving Unsupervised Clean-to-Rendered Guitar Tone Transformation Using GANs and Integrated Unaligned Clean Data
Text-to-Music Editing

[arXiv] [code] [demo]
MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
Instr.-Agnostic Trans.
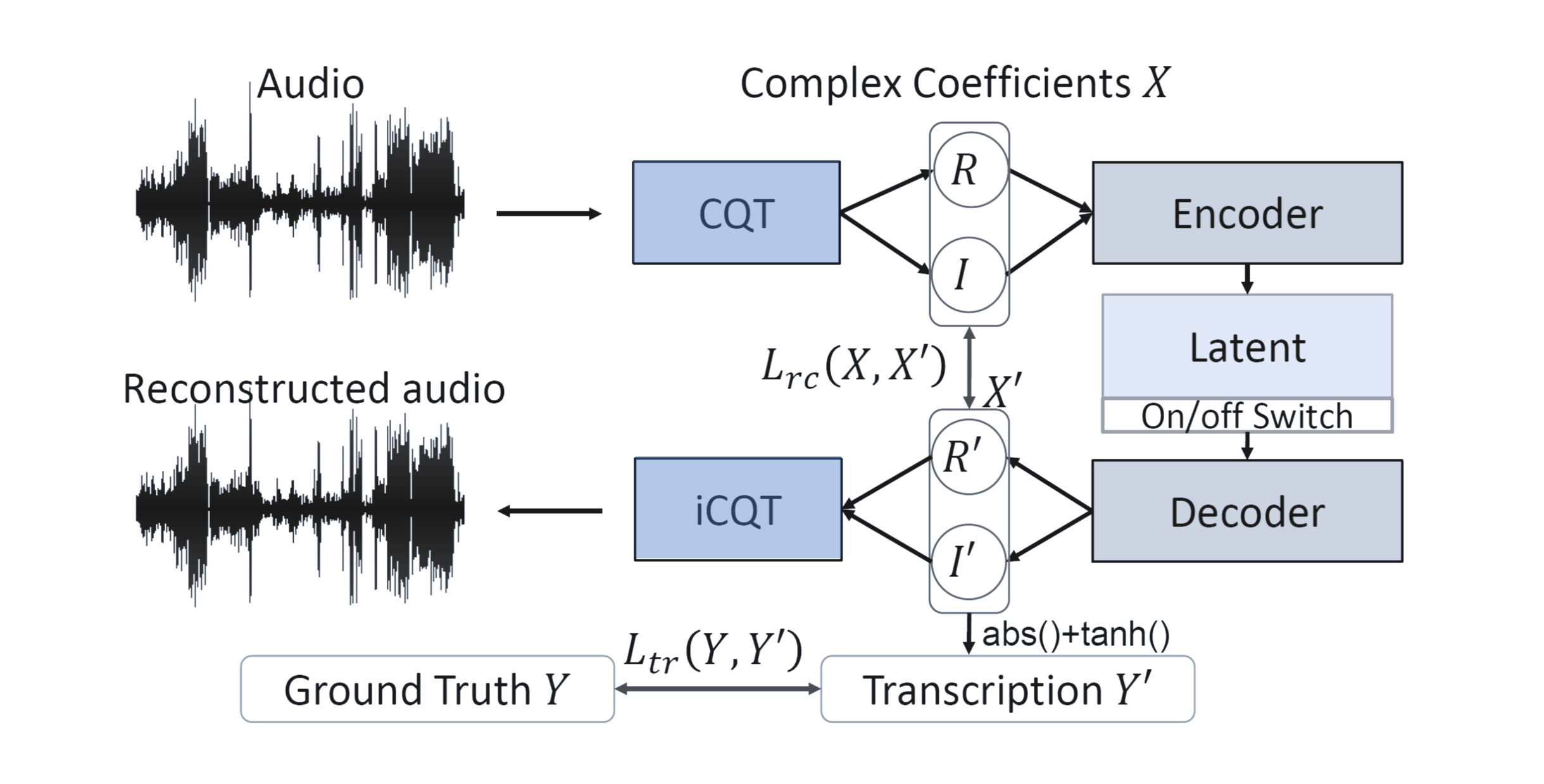
[IEEE] [arXiv]
Timbre-Trap: A Low-Resource Framework for Instrument-Agnostic Music Transcription
Vocal Restoration
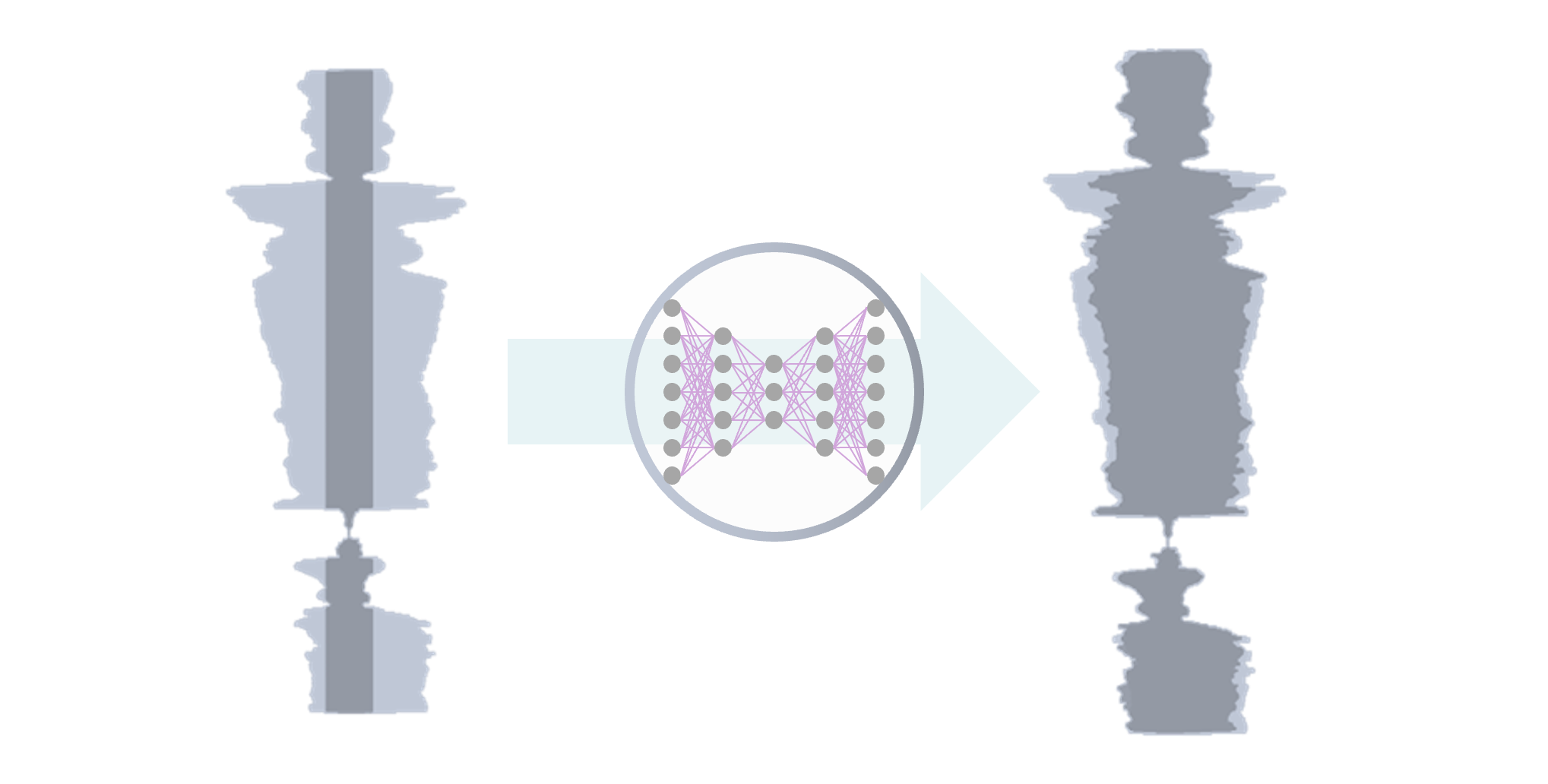
[IEEE] [arXiv] [demo]
VRDMG: Vocal Restoration via Diffusion Posterior Sampling with Multiple Guidance
hFT-Transformer
[arXiv] [code]
Automatic Piano Transcription with Hierarchical Frequency-Time Transformer
Automatic Music Tagging
[arXiv]
An Attention-based Approach To Hierarchical Multi-label Music Instrument Classification
Vocal Dereverberation
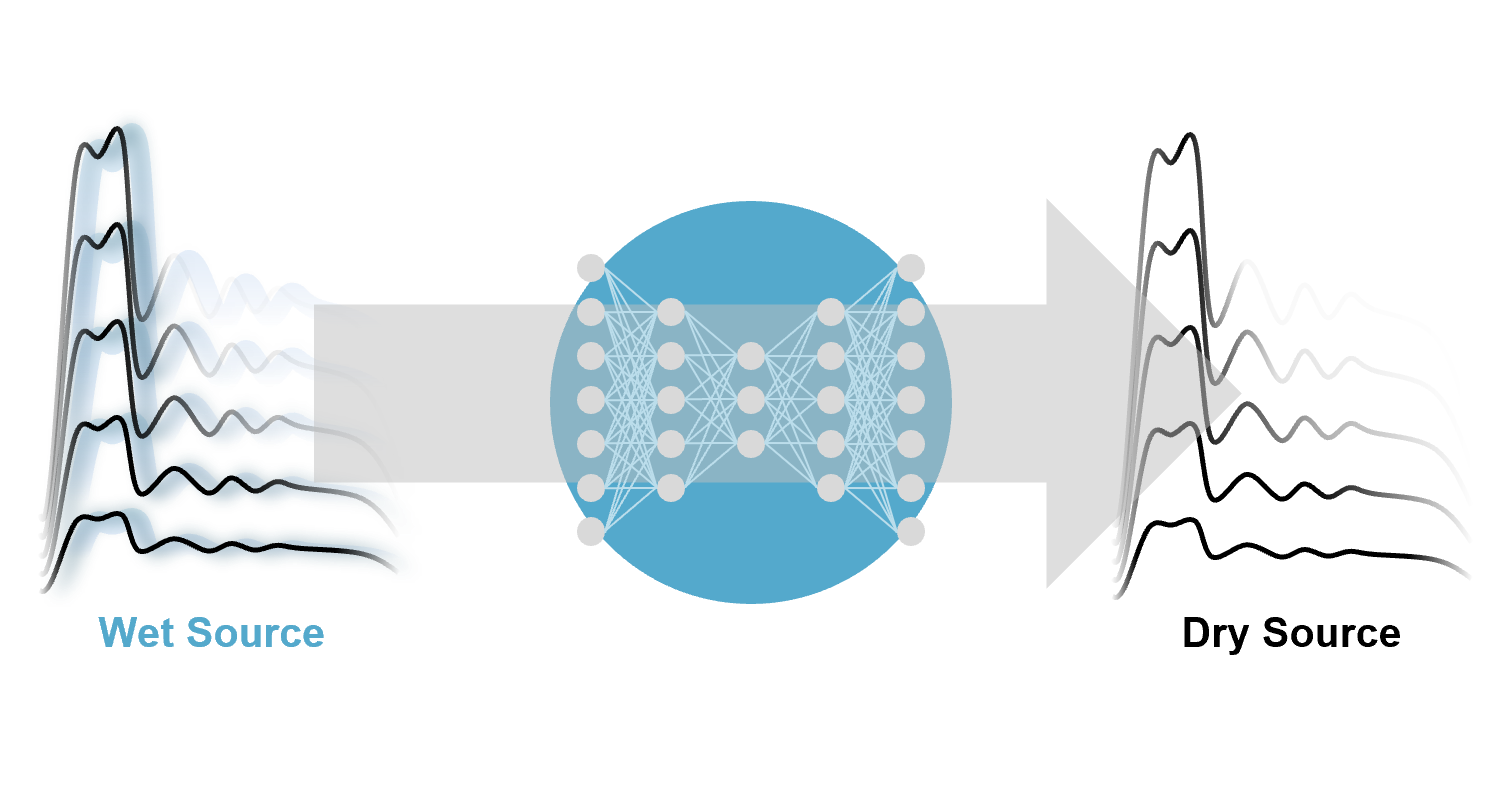
[arXiv] [demo]
Unsupervised Vocal Dereverberation with Diffusion-based Generative Models
Mixing Style Transfer
[arXiv] [code] [demo]
Music Mixing Style Transfer: A Contrastive Learning Approach to Disentangle Audio Effects
Music Transcription
[arXiv] [code] [demo]
DiffRoll: Diffusion-based Generative Music Transcription with Unsupervised Pretraining Capability
Singing Voice Vocoder
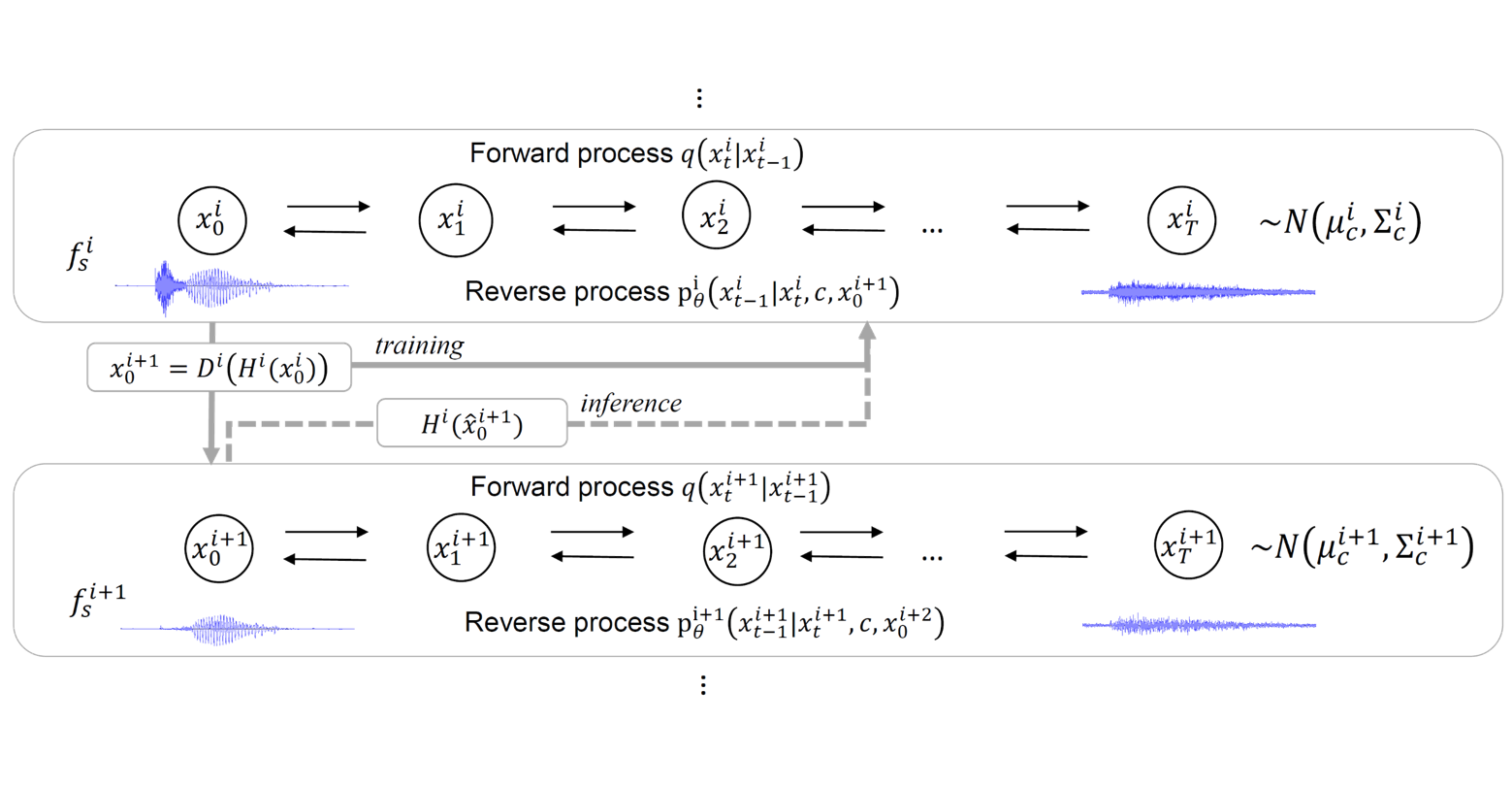
[arXiv] [demo]
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Distortion Effect Removal
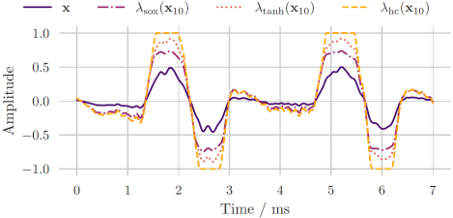
[poster] [arXiv] [demo]
Distortion Audio Effects: Learning How to Recover the Clean Signal
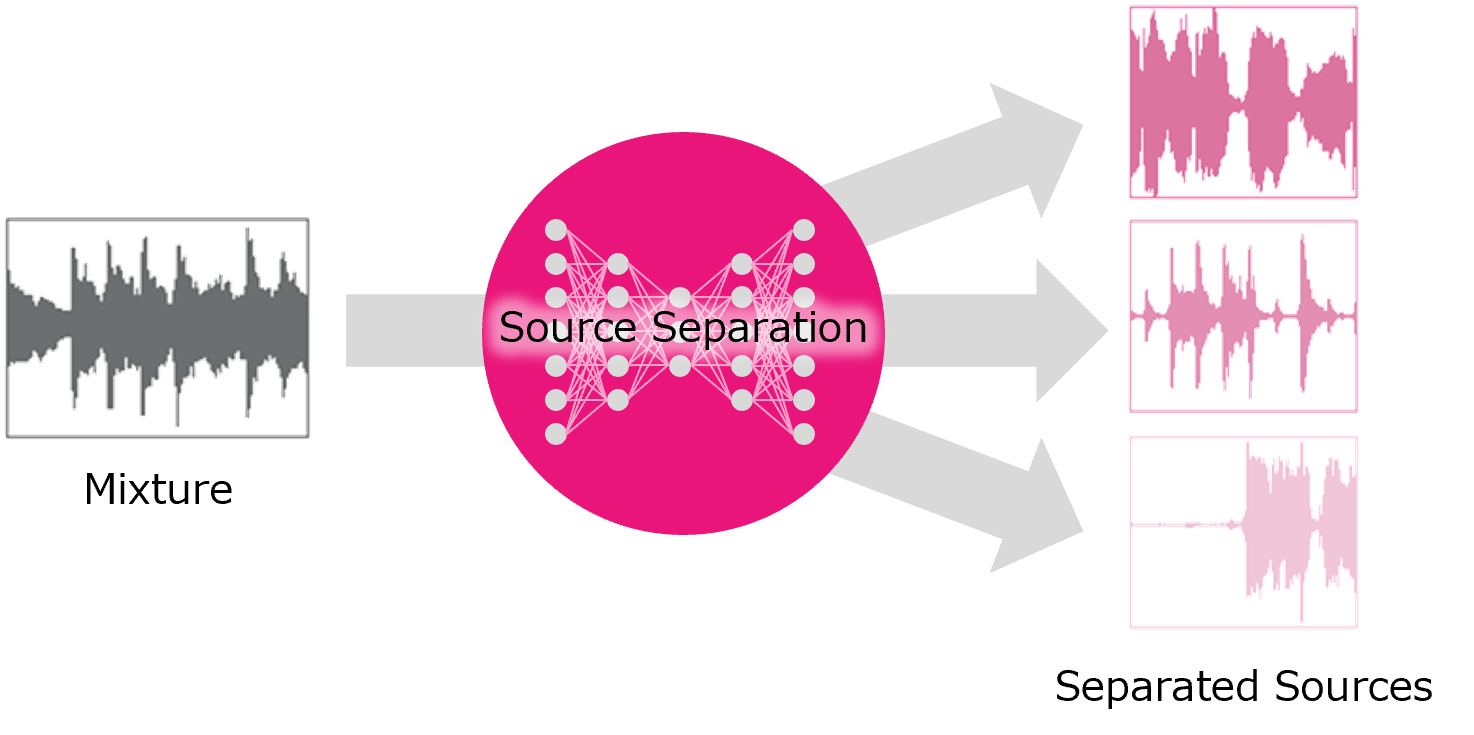
Automatic Music Mixing
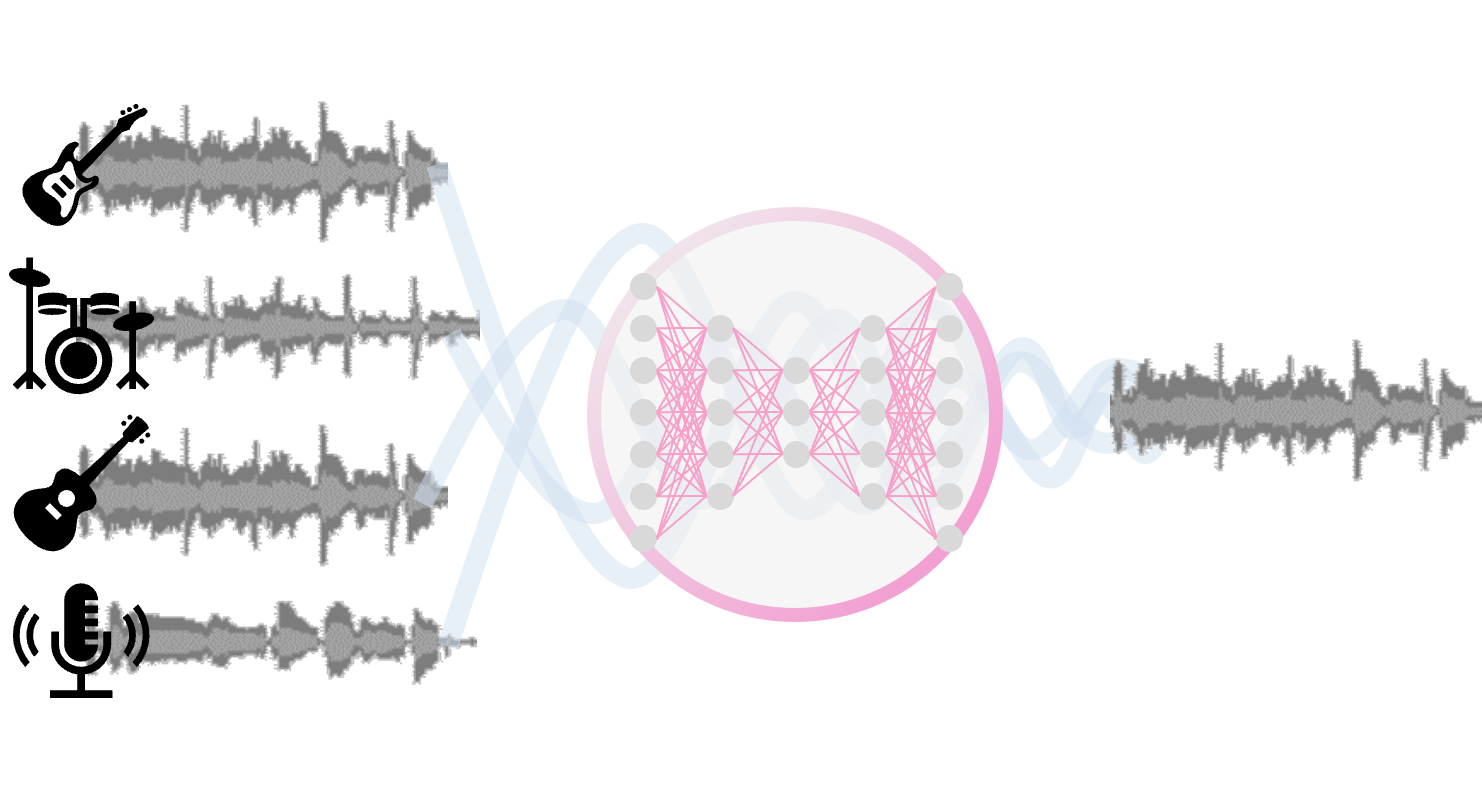
[poster] [arXiv] [code] [demo]
Automatic Music Mixing with Deep Learning and Out-of-Domain Data

Cinematic Technologies
Odoriko
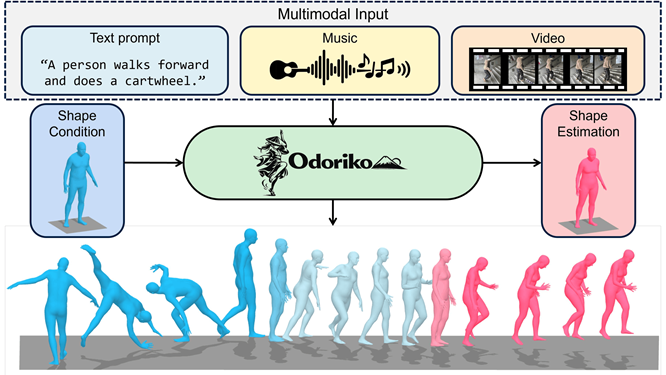
[arXiv] [demo]
Odoriko: A Shape-Aware Multimodal Diffusion Framework for Human Motion
Spectral Alignment (SPA)
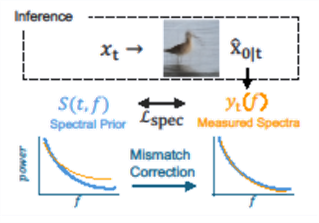
Coming soon
Spectral Prior for Reducing Exposure Bias in Diffusion Models
Step-by-Step V2A
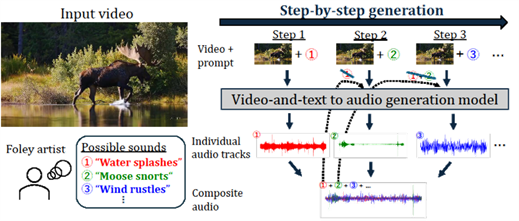
[arXiv] [demo]
Step-by-Step Video-to-Audio Synthesis via Negative Audio Guidance
PAVAS
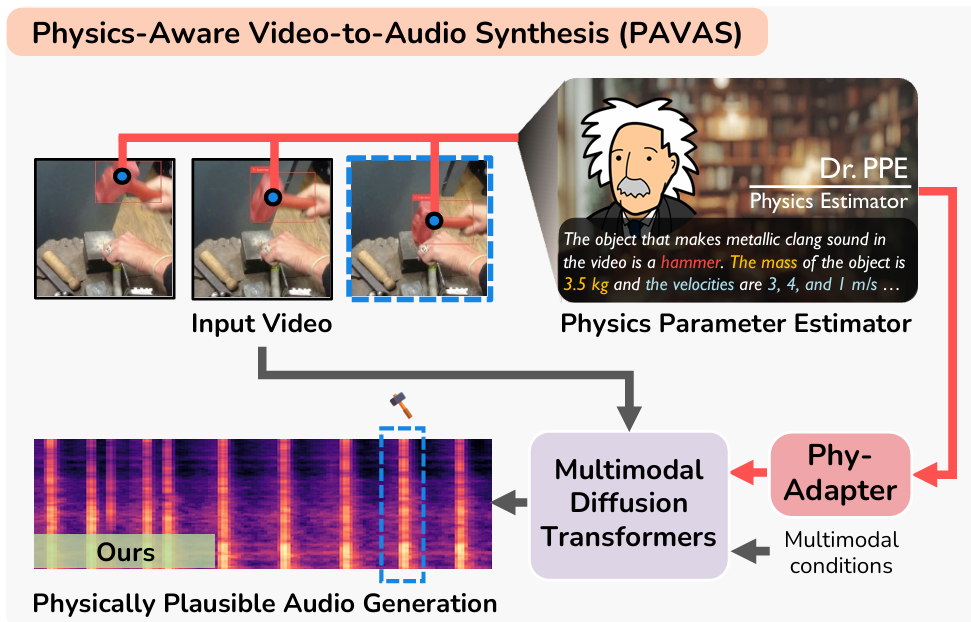
[CVF] [arXiv] [demo]
PAVAS: a framework for generating physically plausible audio from video, by integrating physics estimation
Echoes Over Time
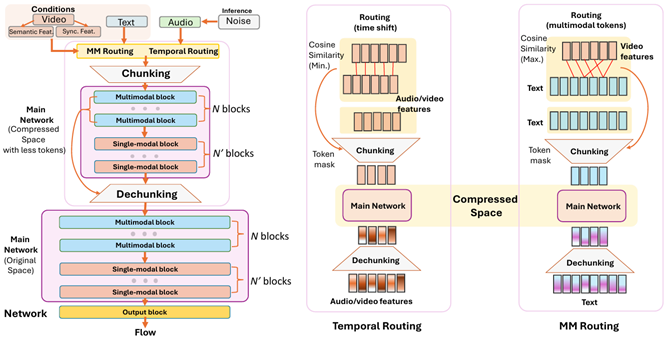
[CVF] [arXiv] [demo]
Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models
VIRTUE

[OpenReview] [arXiv] [code] [dataset] [collection]
VIRTUE: Visual-Interactive Text-Image Universal Embedder
Diffiner for SE & SS
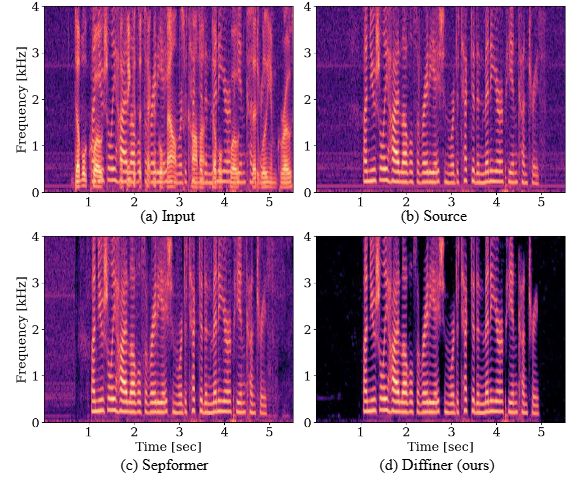
[arXiv]
A diffusion-based post-processor for perceptually improving speech enhancement and separation outputs
CCStereo
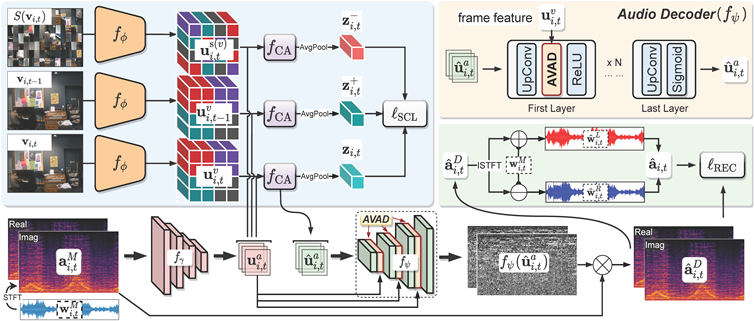
[ACM] [arXiv] [code]
CCStereo: Audio-Visual Contextual and Contrastive Learning for Binaural Audio Generation
TITAN-Guide
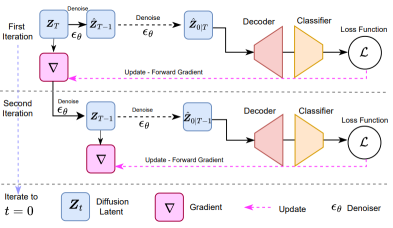
[CVF] [arXiv] [code] [demo]
TITAN-Guide: Taming Inference-Time AligNment for Guided Text-to-Video Diffusion Models
MMAudio
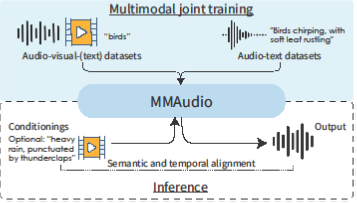
[CVF] [arXiv] [code] [demo]
MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
MMDisCo
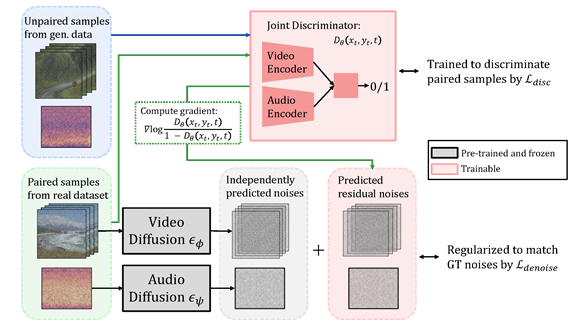
[OpenReview] [arXiv] [code]
MMDisCo: Multi-Modal Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
SoundCTM
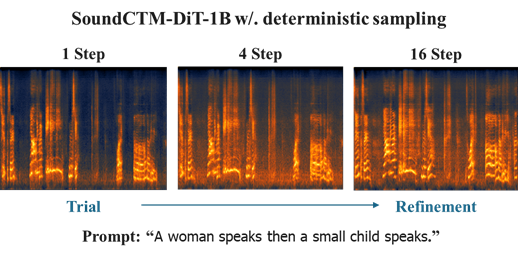
[OpenReview] [arXiv] [code] [demo]
SoundCTM: Unifying Score-based and Consistency Models for Full-band Text-to-Sound Generation
Mining Your Own Secrets

[OpenReview] [arXiv]
Mining Your Own Secrets: Diffusion Classifier Scores for Continual Personalization of Text-to-Image Diffusion Models
GenWarp
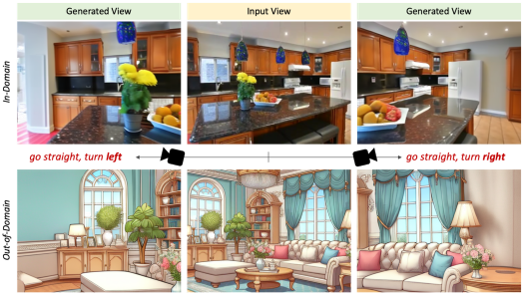
[arXiv] [demo]
GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping
SpecMaskGIT
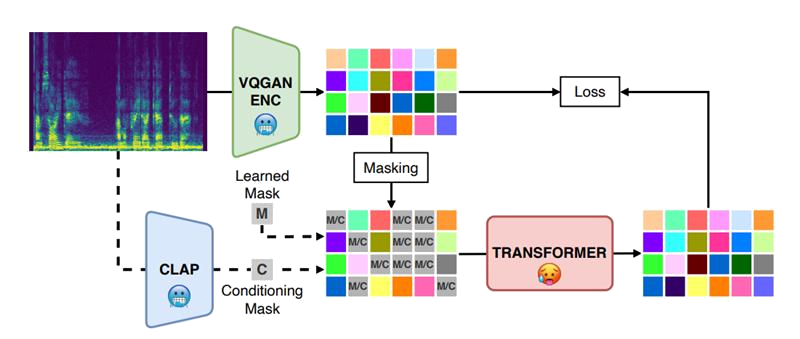
[arXiv] [demo]
SpecMaskGIT: Masked Generative Modeling of Audio Spectrograms for Efficient Audio Synthesis and Beyond
BigVSAN Vocoder
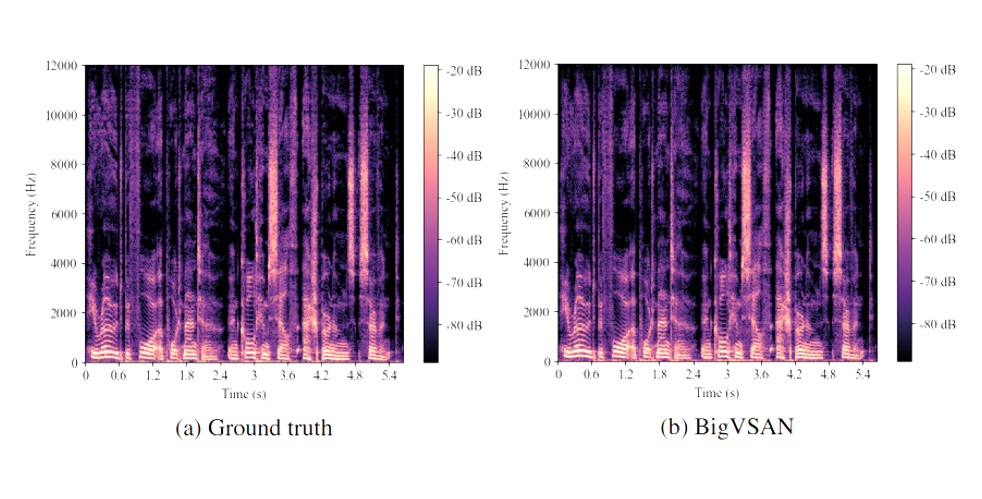
[arXiv] [code] [demo]
BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network
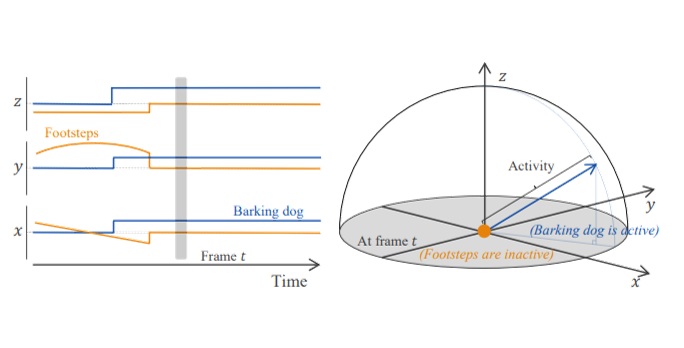
Zero-/Few-shot SELD
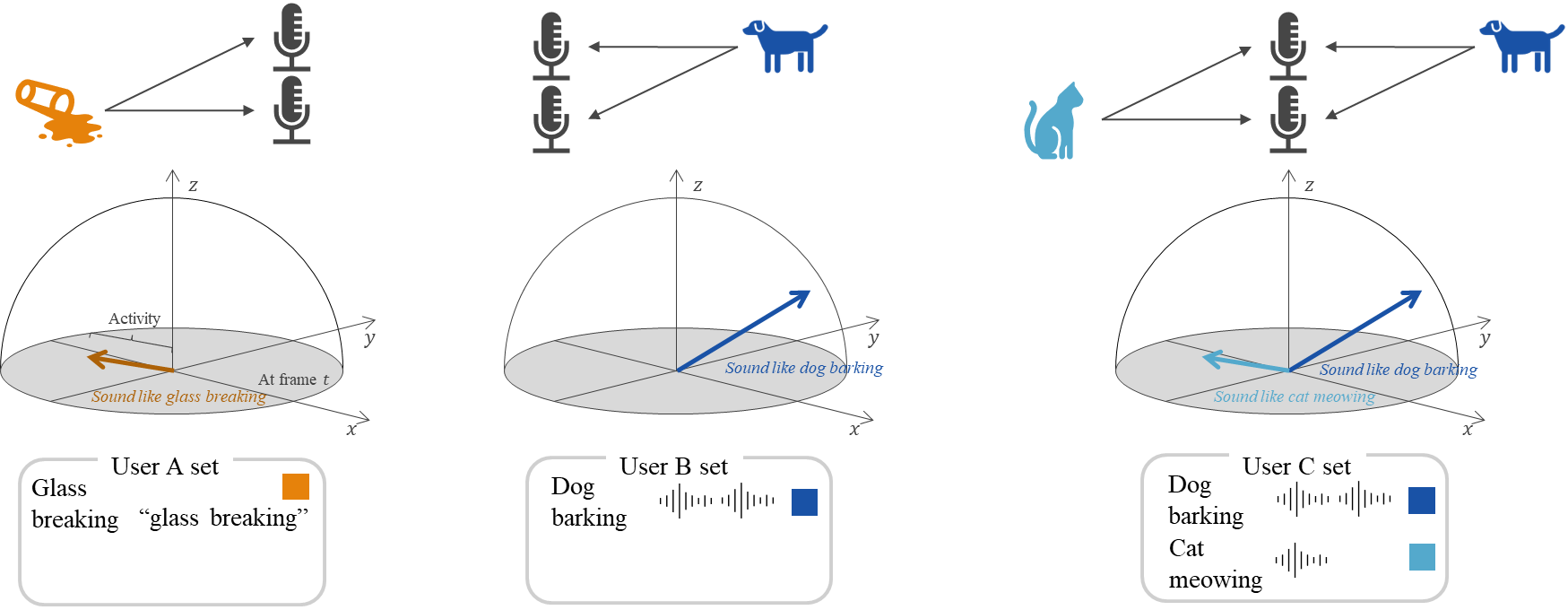
[IEEE] [arXiv]
Zero- and Few-shot Sound Event Localization and Detection
STARSS23

[arXiv] [dataset]
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
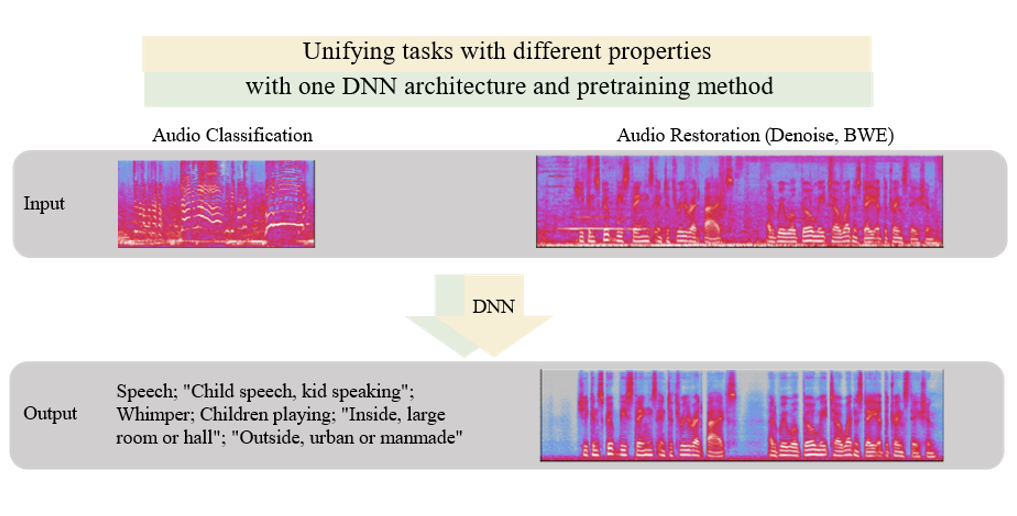
Audio Restoration: ViT-AE
[IEEE] [arXiv] [demo]
Extending Audio Masked Autoencoders Toward Audio Restoration
Diffiner

[ISCA] [arXiv] [code]
Diffiner: A Versatile Diffusion-based Generative Refiner for Speech Enhancement
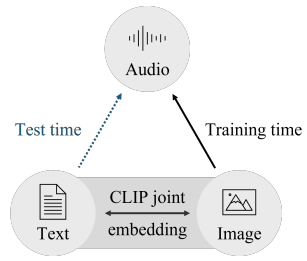
CLIPSep
[OpenReview] [arXiv] [code] [demo]
CLIPSep: Learning Text-queried Sound Separation with Noisy Unlabeled Videos
Hosted Challenges
DCASE Challenge Task 3

[DCASE Challenge2026]
Semantic Acoustic Imaging for Sound Event Localization and Detection from Spatial Audio and Audiovisual Scenes